My 6 Months Interning Responsibly at AI Practice

Tell us about yourself- what did you expect from this internship?
I’m Rohan, a penultimate year Business Analytics student at the National University of Singapore (NUS) who spent the first half of 2026 as an applied AI Data Scientist Intern at GovTech’s Responsible AI team.
Going in, I expected the typical data science internship- train a model, optimise some metrics, and maybe deploy some classifiers here and there. What I did not expect was to do all that whilst gaining new perspectives on how we view AI systems. It turned out that the harder and more interesting question isn’t just “can we build this?” but “can we prove it works safely for everyone?” That reframing caught me a little off guard, and that is what made my experience all the more compelling!
What did your day-to-day look like on the Responsible AI team?
It varied a lot depending on the phase of the projects I was working on. Some weeks, I was deep in experimentation, iterating over multiple different strategies and approaches until the numbers told a clear story. However, there were also many weeks of pure engineering- building different async pipelines, multi-provider LLM orchestration across multiple backends, and of course, integrating the results from our experiments to deployment.
I found that to be the unique characteristic of the Responsible AI team as it sits at the intersection of research, governance, and production, working from ideation to deployment. The ability to spend different parts of my internship working on these different aspects kept things interesting throughout.

Can you walk us through what you worked on?
My main project was Kaleidoscope- a now open-sourced evaluation workflow that lets government agencies and any other user connect any chatbot and evaluate it across custom metrics they are able to define themselves. It can be thought of as a quality assurance system for AI where users plug-in their chatbot, define what “good” looks like (maybe in terms of empathy, accuracy or even policy compliance), and Kaleidoscope automatically scores responses using LLM judges.
I owned the custom metrics system- the core of how users define and evaluate arbitrary quality dimensions. This meant a literature review, designing the architecture, running weeks of experimentations to validate it before building it into the workflow.
I also owned RAI Bench, a public safety benchmarking leaderboard contextualised for Singapore. This meant keeping up with the latest model releases, evaluating them for safety, robustness, and fairness, and publishing results to a public-facing leaderboard. I then extended the pipeline to support guardrails benchmarking- integrating six commercial and open-source content moderation providers (from the likes of OpenAI and AWS) and normalising their different output formats using a developed taxonomy mapper.
Additionally, I worked on developing custom guardrails for an agency citizen-facing chatbot. Off-the-shelf moderation systems do not understand Singapore-specific context, policies, or even Singlish. Developing custom guardrails meant taking defined safety policies and designing multi-strategy synthetic data generation pipelines and training classifiers. We also had to build the evaluation framework, not just to identify and fine-tune the best model, but to also calibrate the safety-utility tradeoff because a guardrail that is too aggressive is just as much a failure as one that's too permissive.
What were some challenges you faced?
The current AI landscape moves fast with new models being released constantly, and each one needs to be evaluated before claims can be made about its safety. Keeping the RAI Bench and other work updated meant constantly adapting to new model architectures and API changes. Observability became increasingly important here. I instrumented my projects with Langfuse tracing which let us pinpoint exactly where models were failing: was it the connection, the model, or an unforeseen error we hadn’t picked up? Without this tracing, debugging across multiple models and pipelines would have taken much more guesswork.
For the custom guardrails project specifically, the technical challenge was synthetic data quality. LLM-generated prompts tend to be too clean, too articulate, and don't reflect how real users actually type (especially in Singlish). We had to design multi-strategy generation with diversity controls and validation loops to ensure the classifiers wouldn't just overfit to surface patterns in the synthetic data which eventually produced training sets that held up against real user behaviour.
However, across my internship, one of the biggest challenges I faced was while working on Kaleidoscope. The question sounded simple: how do you get an LLM to reliably judge another LLM’s output?
After a literature review, we started by defining brackets of related metrics- "voice" (empathy, structure etc.), "relevancy" (sensibleness, specificity etc.), and “accuracy” (faithfulness, factual correctness etc.)- and tried to find one generic template per bracket that could evaluate all its dimensions in a single call. For each bracket, we tested across different models, temperatures, and prompts and validated everything against over 100 Q&A pairs that we had manually annotated to be used as the ground truth.
Despite all our efforts, it didn’t work and the results were poor. I had to accept that the architecture itself was the problem. When you ask a model to evaluate multiple dimensions simultaneously, it distributes attention across all of them, and the subtle metrics tend to get drowned out by the more straightforward ones. No amount of prompt engineering would have been able to solve this.
So how did you solve this problem?
We pivoted to dedicated single-dimension judges where one judge evaluates one metric, rather than multiple. It sounds obvious in hindsight, but the improvement was immediate, with results improving by over 20% on average across the board. Those became our production “preset” metrics in Kaleidoscope.
This solution then created another problem- presets do not scale. It got us back to the drawing board to account for users defining their own custom metrics.
We decided to build an additional augmentation pipeline. When a user writes a custom rubric, an LLM transforms that definition into a full judge prompt, complete with calibration notes, reasoning structures, and failure-pattern definitions. We tested this across different augmentation models and levels of rubric detail to find what worked best for this use case.
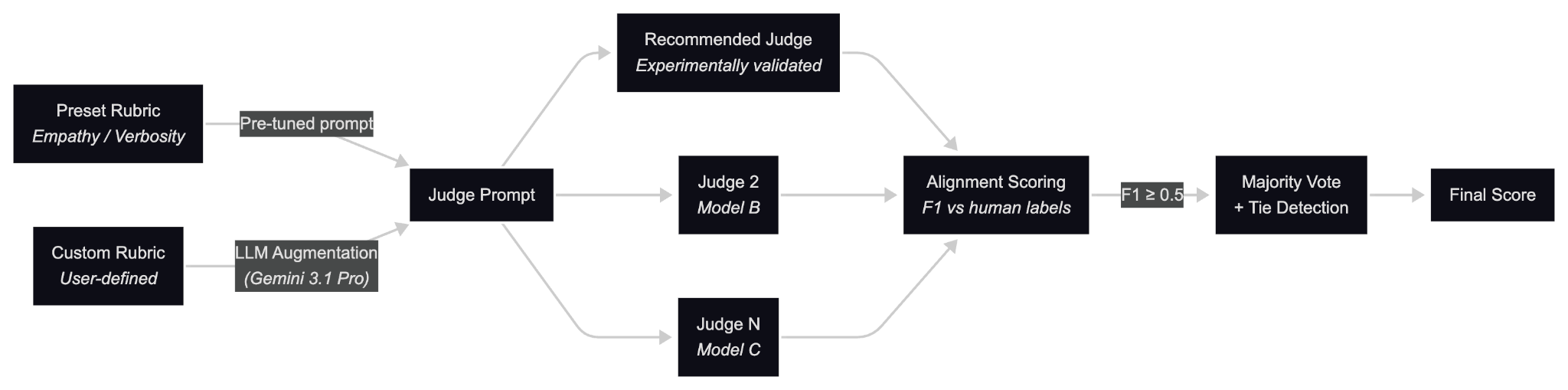
The whole journey, with over 100 evaluation runs, and countless iterations, taught me things I could never have learnt in any classroom. Sometimes the hardest engineering problems in AI are not about the model, but about measuring it.
What are some takeaways from your experience?
These six months have definitely taught me a lot in more ways than one. One key lesson from my work would be how to navigate projects with no fixed solution or answer key. It may be uncomfortable at first, but I feel that was where I learnt and grew the most. Having to read the literature, propose a direction and defend your results is where you take ownership of your work, and where lessons stick in a way that following instructions never achieves.
Outside of my projects, I thoroughly enjoyed and learnt a lot from the biweekly AI/ML community sharings. Be it work projects, hobby side-quests or uncovering new technologies, these sessions allowed me to delve deeper into the various other aspects of the AI landscape, and gave me a window into what everyone else was working on across the department. It was a good reminder that sometimes, learning does not just come from your own work, but how others approach different problems. The good food afterward didn’t hurt either 😈.

Overall, this internship gave me something I don’t think I would’ve found easily anywhere else- the opportunity to work on something both technically deep and genuinely meaningful. I’m deeply grateful to my team at Responsible AI for not just their support and guidance, but for trusting me with this opportunity. I hope to continue such work in the AI space in the near future 😁!