Building an automated Evals workflow that works (and open-sourcing it)
How we built Kaleidoscope: A structured workflow for realistic, scalable, and human-aligned contextual AI evaluations.


You need evals
If you've been working with AI, whether it's a chatbot, an LLM-powered automation pipeline, or an agentic assistant, you've probably asked the same question we did: is there a way to measure whether this AI application is doing what it's supposed to do?
That's what AI evaluations, or "evals", are for. Evals are the process of measuring the abilities of an AI system to understand how well it performs and to improve it. Think of it as software testing for AI, except the outputs aren’t deterministic, failures are subtle, and “correct” is often subjective.
We think of evals as a loop. You define specific criteria, generate test cases, measure performance, and use the results to improve the system. In practice, evals have become a core part of the development process.
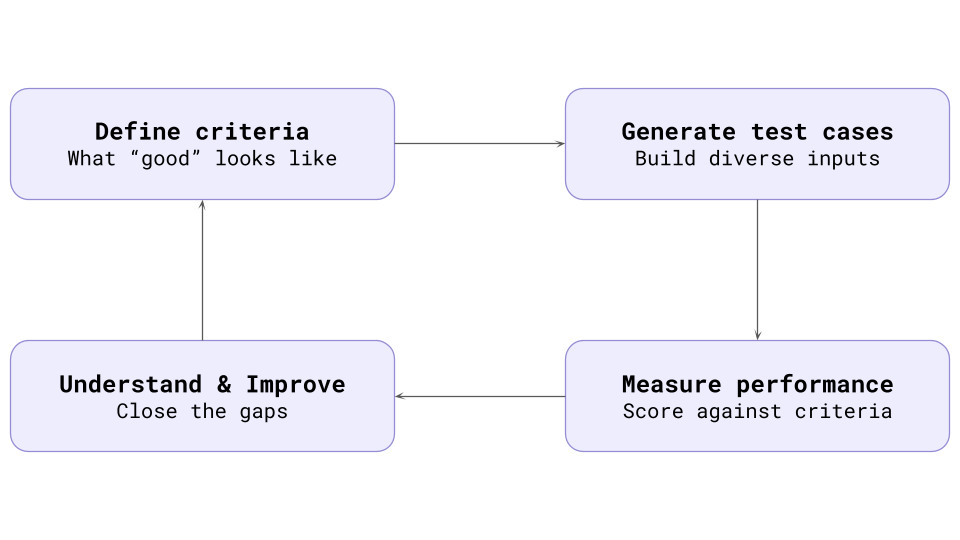
The problem with Evals today
With agentic coding tools like Claude Code and Codex today, it’s never been easier to build an AI app. The problem comes when you try to move from prototype to production and need to evaluate whether it’s actually ‘good enough’.
Existing tools have made evals more accessible, and many work well for safety testing or static benchmark evaluations. Functional evals, however, are much trickier because of how product-specific they are: what counts as “good” depends entirely on the application context.
As we spoke to more teams building real-world AI applications, we found a recurring gap: contextual functional evals are difficult to do well. Some teams didn’t know where to start. Others could run evaluations, but struggled to make them realistic or scalable. Here are two scenarios we hear all the time.
The business owner
The business owner who evaluates the app...
The business owner evaluates the app before it goes into production. They begin by curating a set of test inputs with golden outcomes, running them through the application manually, and slowly reviewing the responses. They find that this method scales poorly — it's hard to come up with diverse test cases, to run them against the app, and to review the long AI reasoning chains.
The engineer
The engineer who builds the app...
The engineer builds the app. Their initial instinct is to ask the very agent who created the app to come up with some test cases. Then they realise - the generated prompts often become repetitive, unrealistic, or sometimes outright nonsensical. The agent is great at building, but it doesn't know the users.
They turn to existing open-source frontier benchmarks. More often than not, there isn't one that matches the application's purpose perfectly, and general benchmarks can't reveal the nuances required to ensure a model performs on a specific workflow in a specific business setting.
Even when they have the right test cases, there's the question of how to grade the app's performance. Using an LLM-as-a-Judge is increasingly common, but it introduces its own risks and uncertainty.
Across these conversations, a few key challenges and concerns kept surfacing.

These concerns shaped Kaleidoscope: a structured evaluation workflow designed around optimising human-aligned evaluation workflows. We realised that good evals are not just about automated scoring — they also require representative datasets, configurable evaluation criteria, transparent judge behaviour, and user-friendly review workflows.
Introducing Kaleidoscope
In this workflow, we focus on input–outcome evals. Kaleidoscope breaks down the evaluation workflow into three core parts:
- Defining what you wish to evaluate
- Gathering representative test cases
- Scoring and analysing responses in a scalable and aligned way
Just as importantly, the workflow is designed to make results easy to review and analyse. Users should be able to quickly inspect outputs, identify failure patterns, and understand where improvements are needed.
Here’s how each part works.
1. Defining the evaluation rubrics
Defining custom rubrics is one of the most important steps in the evaluation process. What does "good" look like for your specific application? What criteria matter most?
In Kaleidoscope, users define rubrics through a guided workflow. Each rubric has a description of the evaluation criteria and a set of outcome labels (e.g. “Accurate” vs “Inaccurate”). Once saved, Kaleidoscope uses an LLM to automatically generate a structured judge prompt from your criteria.
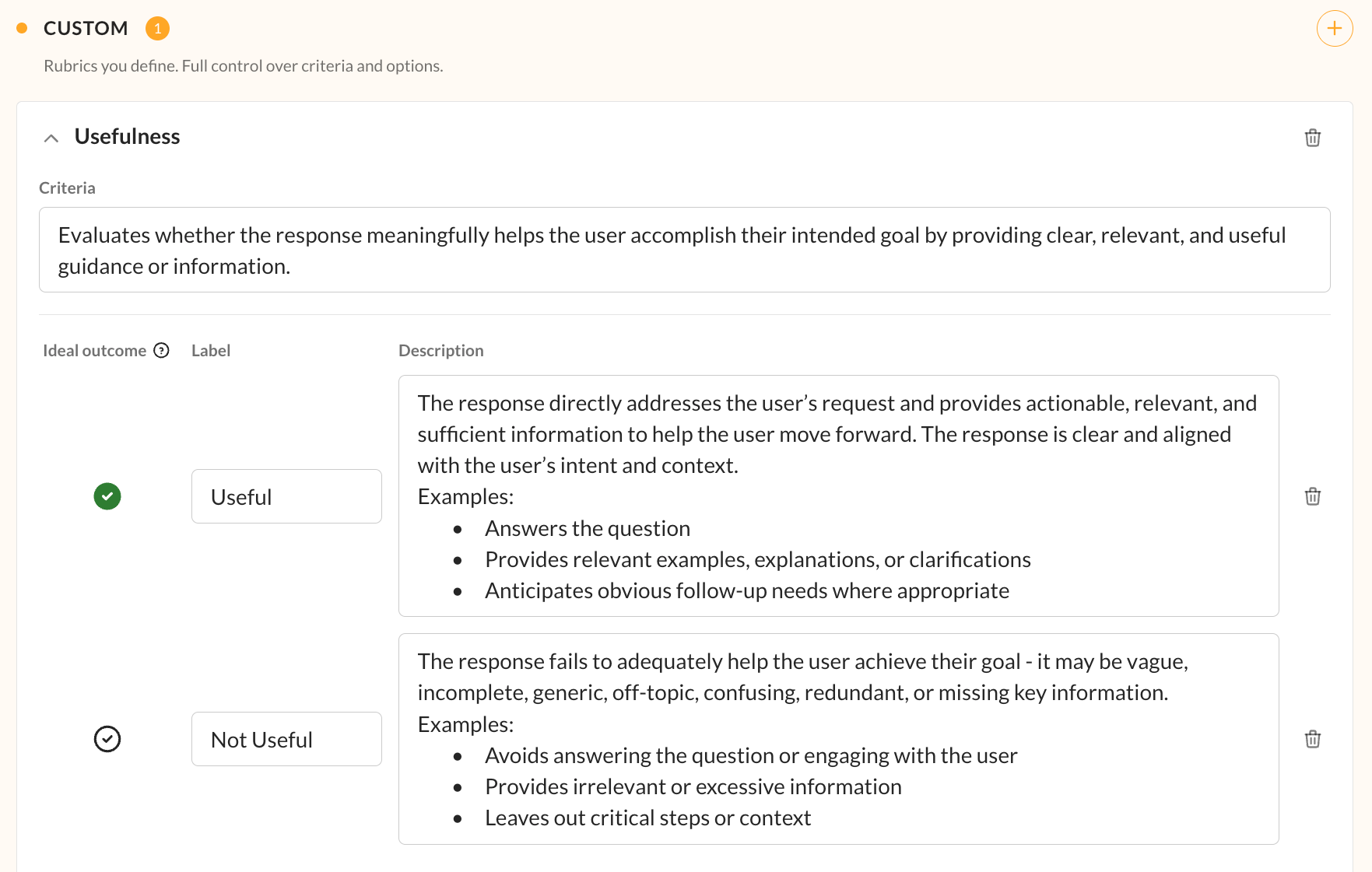
Describe what you’re evaluating in natural language and Kaleidoscope handles the rest.
The tool ships with a small library of pre-set rubrics to get you started. Accuracy is attached by default, which uses a claim-based approach that combines commonsense and groundedness scoring. Answers are broken down into individual claims and checked against the provided knowledge base, then aggregated up to a response-level verdict. This gives much more granular insight into where an answer goes wrong, rather than just whether it went wrong.
Beyond accuracy, users can optionally add Empathy (does the response demonstrate emotional awareness appropriate to the user’s situation?) and Verbosity (is the response appropriately concise?). These presets come with specifically designed judge prompts, which we tuned through several rounds of aligning judge scores with human labels.
2. Gathering representative test cases
To simulate an application's target audience, Kaleidoscope powers test case generation with user personas.
Think of it like writing a book. Authors map out their characters' backgrounds and personalities before putting them into scenes. Similarly, the more context we give the data generator about who the users are, the more realistic the generated test cases turn out.
Defining personas can be done in multiple ways: using another AI to generate them from the application’s context, manually defining user archetypes based on domain knowledge, or sampling from open-source persona datasets (NVIDIA’s Nemotron-Personas is one that provides thousands of pre-defined personas across selected demographics).
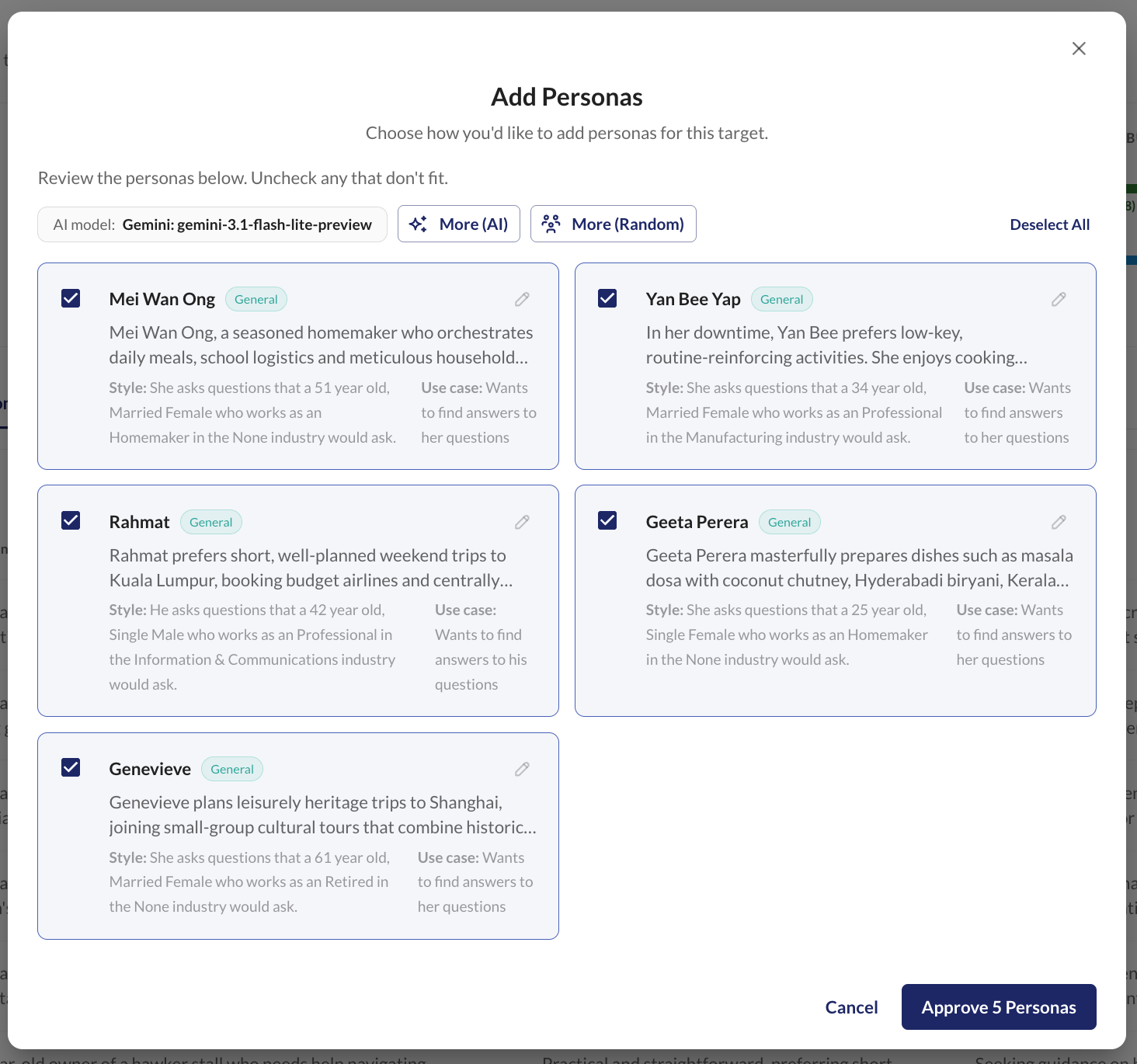
These personas are paired with your application context and knowledge base to generate test cases. Application context (such as the product information and knowledge base) determines the content of the input. For example, a first-time user might produce a simple, straightforward input, while an expert flagged as an edge case might produce something nuanced that pushes the boundaries of your app.
Personas determine the tone, complexity, and intent of each input, reflecting how a real user with that background would interact with the app.
Users should set up multiple detailed personas and generate a small batch of test cases for each. Combined with diversity parameters like input style and scope, this ensures the synthetic evaluation set covers a wide and diverse range of realistic scenarios and better predicts post-deployment performance.
3. Responsible scoring with an LLM judge
Keeping the Human in the Loop
Here's the dilemma that we have been wrestling with thus far: you either keep the human in the loop, or you accept the risks of fully automated evaluation. Most tools today accept the risks (understandably, given how capable models are these days). But in high-stakes domains, we still want to stay accountable for the level of autonomy we give to AI systems.
Human oversight is still needed, even with automated evaluators
The problem is, human review today is painful. Research on decision fatigue shows that decision quality drops with repeated judgments, while studies on annotation interfaces found that well-designed interfaces can significantly reduce annotator fatigue. Yet most evaluation tools still require people to read through long paragraphs of AI-generated text and make complex judgments.
We wanted to keep humans in the loop without making the review process exhausting. That shifted our focus toward the annotation experience: breaking responses into smaller, reviewable chunks and presenting judge verdicts in a way that is easy to review.
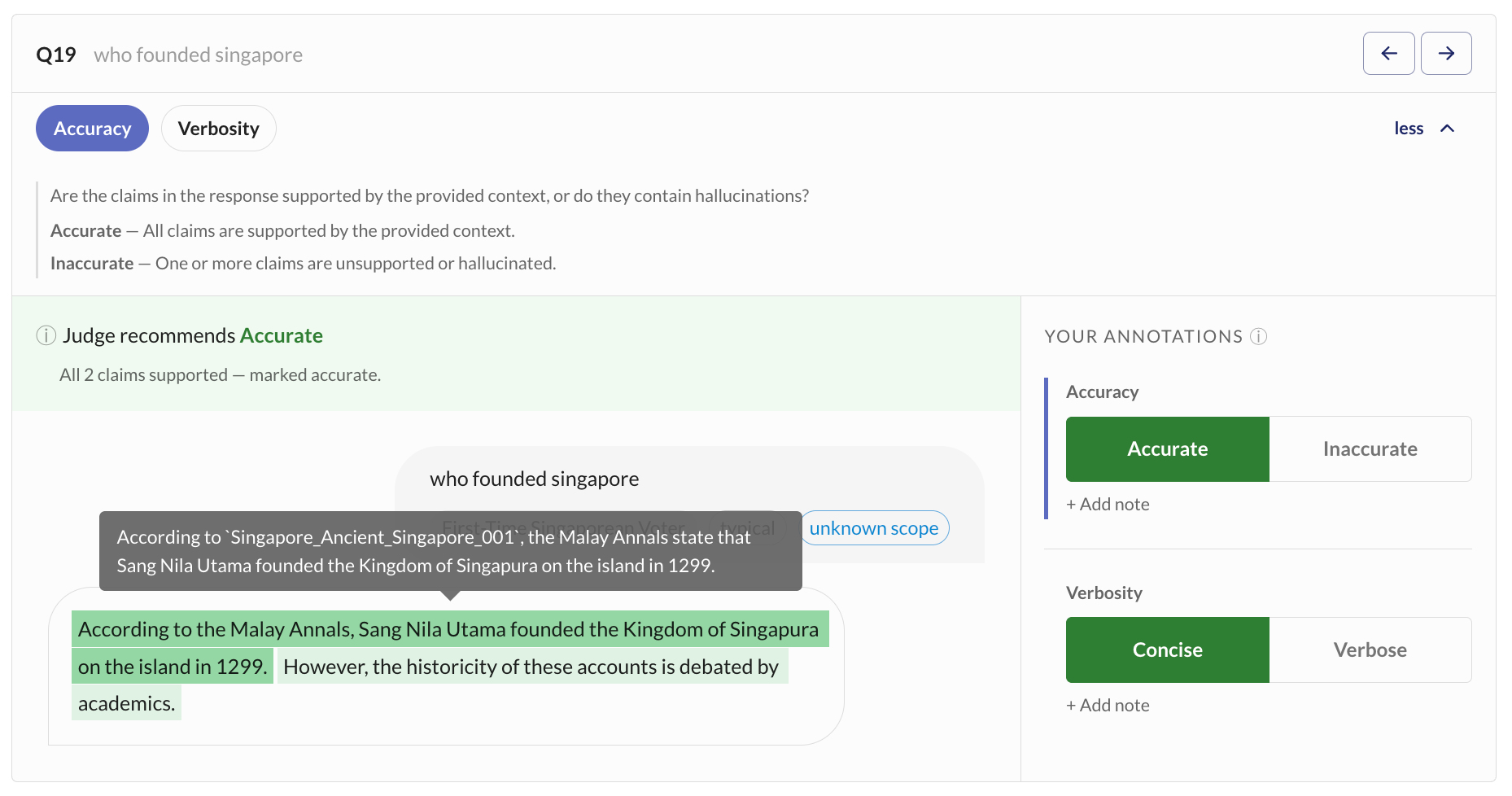
Using that to measure Judge reliability
This annotation UI isn't just about making human review easier. It also gives us a way to measure how aligned the LLM judge actually is. Instead of letting the LLM judge score your entire dataset unsupervised, we calibrate it against human-annotated examples:
- Select a random subset of the evaluation dataset.
- A human expert labels that subset
- And those human labels are compared against the LLM judge’s scores to calculate alignment/reliability (F1 score, precision, and recall).
The idea is simple: you can use any LLM as your judge (yes, even small LMs), as long as it hits a certain alignment threshold.
We also recommend using a jury of judges: multiple LLMs scoring independently. The same set of human annotations can be used to calculate reliability for more than one judge, and only those that meet the threshold contribute to final scores.
Users have full control over their jury setup. They can modify the preset judge prompts, swap in different LLMs, or create custom judges from scratch to find the combination that works best.
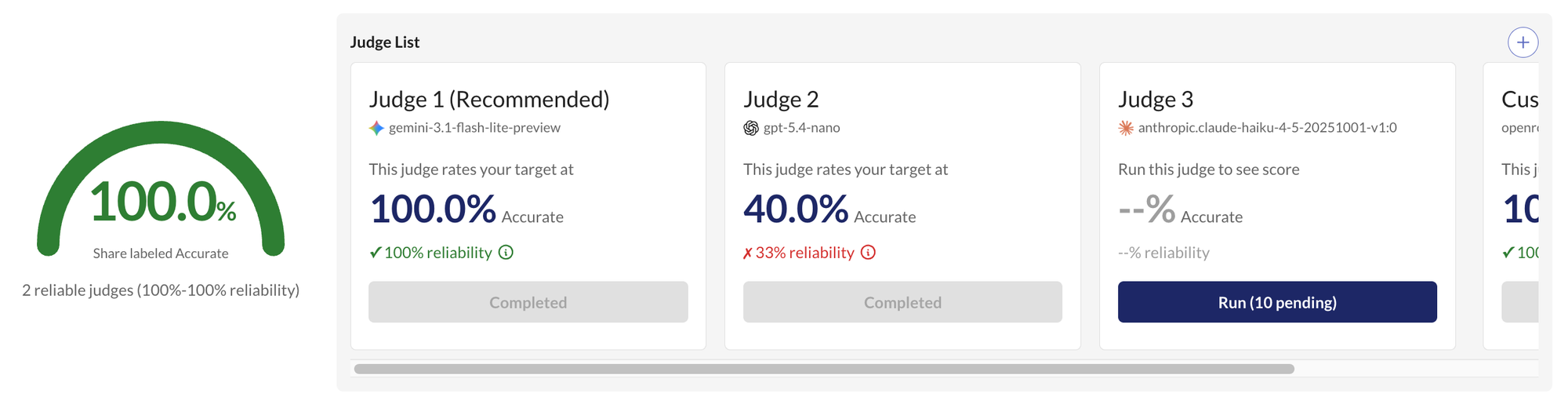
The benefit of multiple judges goes beyond reliability. You can compare where they disagree – those disagreements point to ambiguous or subjective cases that need more attention. Kaleidoscope surfaces these disagreements in the UI, where you can filter by disagreement cases and compare each judge's verdict.

The Next Step: Closing the Loop
Today, Kaleidoscope helps you measure and understand your application’s performance. However, the eval loop doesn’t stop at measurement.
In the near future, we aim to build an improvement feedback loop directly into the workflow, closing the flywheel so that evaluation results can inform better prompts, better retrieval, and better outcomes.
Kaleidoscope for Singapore
Kaleidoscope is designed as a general-purpose evaluation workflow, but we’ve also included several extensions for Singapore-specific use cases:
- Integration with Nemotron-Personas-Singapore: pre-built personas drawn from NVIDIA’s Singapore-specific persona dataset
- Localised test case generation: prompts tailored to Singaporean contexts and language usage
- AIBots integration: evaluate your AIBots chatbots without manual export/import of responses.
For Singapore government agencies who are interested in a centralised, hosted platform, indicate your interest here and we’ll get back to you real soon ;).
Kaleidoscope brings all of this together into one open-source tool for contextual AI evaluations.
While it started as a workflow for chatbot evaluation, the approach generalises to any input-outcome evals with the right context, and we welcome contributions to extend it to new use cases and workflows!
We'd love to hear how your team approaches evals today. What's working, what's not, and where the gaps are. If any of this resonates, give Kaleidoscope a spin and let us know what you think!: