The Road Under the Harness
Previously I wrote about building a harness for yourself. This one is about the environment you're building in, and why at enterprise scale, if the platform underneath doesn't exist, individual wins have nowhere to accumulate.

After you built your harness, then what?
In "Harnessing the Harness", I wrote about building a personal orchestrator, Terra. One engineer, one laptop, a fleet of Claude Code sessions managed with bash, tmux, and my own quirky heuristics. The idea was to build your harness, own your harness, and evolve your harness, in a way that works best for you.
But there's a version of that story that doesn't work, and you'd probably find it familiar. You build your Terra-equivalent. It's great. You try to hook it up to your internal documentation, and realise you need VPN credentials that you can't safely give to a long-running process. You try to share it with a colleague, and realise it's full of paths that only exist on your machine. You ask about using it on production data, and get hit with all sorts of compliance issues you never knew existed.
None of those are technical failures. They are environmental ones. The harness you built was right for an environment of one, but not for the environment you actually work in.
tl;dr: In this piece I'll be discussing why owning your agentic platform matters for every organisation, and the whys and hows of going about it.
Let's talk about a chart
DORA published their 2025 State of AI-Assisted Software Development report in October. Buried in it is this chart. It plots the effect of AI adoption on organisational performance against the quality of the organisation's internal platform.
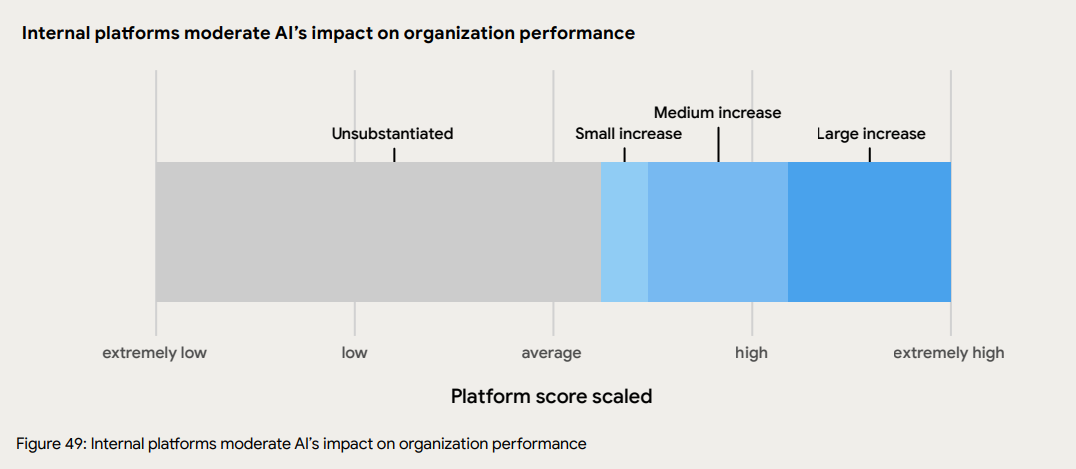
The chart has a single axis: platform quality, running from extremely low to extremely high. Above it sits one long bar, divided by colour. Each coloured region corresponds to the size of AI adoption's effect on organisational performance at that level of platform quality. From "extremely low" through "average," and for some distance past it, the bar is grey. The label on that grey region reads "Unsubstantiated."
Only past the "average" mark does a small blue band appear. It grows into a medium-blue band, then a dark-blue band as platform quality climbs. DORA summarises the finding as "AI adoption has a negligible effect on organisational performance when platform quality is low, but when platform quality is high, the effect is strong and positive."
Two caveats I want to highlight. First, DORA surveyed software organisations, so "organisational performance" here is a software-delivery construct, not a generic productivity measure. Second, DORA separately shows that AI adoption has a positive effect on individual effectiveness. Developers using AI do get faster. Officers using Cowork will draft faster. The chart isn't claiming otherwise.
The study's domain is software, but the mechanism is general. Individual productivity gains failing to aggregate into organisational outcomes (without the right environment underneath) isn't a software-specific pattern. Any large organisation adopting AI is about to run into the same dynamic, whether the work is software, policy, finance, regulatory response, or service delivery. What the chart captures in DORA's sample is what the rest of the enterprise is about to feel in the next few years.
Which is the more interesting reading of the chart. Individual gains from AI are real, but they don't automatically aggregate into organisational performance. Something happens between the individual win and the organisation feeling it, and in most cases, that something is a substrate that either captures the gain or loses it.
AI for the individual vs AI for the enterprise
There's a temptation to talk about "enterprise AI" as a category of agent. A beefier Claude, a more governed GPT, a business-grade Cursor. I think that framing is wrong, because "enterprise" isn't a property of the agent: it's a property of the environment the agent has to operate in.
AI for the individual optimises for you. Your taste, your speed, your idiosyncrasies. A Terra built for me is deliberately opinionated because I'm the only one who has to live with the opinions. The feedback loop is tight. If it breaks, I fix it at midnight. If the pipeline produces something weird, I read the logs myself. If the agent picks the wrong model, I edit a role file. Every decision is reversible in under ten seconds because one person makes all of them.
AI for the enterprise optimises for invariants. Things that must be true regardless of which person, team, or use case is involved. That an agent cannot see data it's not supposed to see. That a trace exists for every action it took. That the credentials it used belonged to a scoped agent identity, not some engineer's personal token. That the context it relied on is versioned. That if the agent misbehaves, you can tell which agent, on which prompt, from which source, acting on whose behalf.
That's a different design brief altogether. You are not optimising for throughput on a single task. You are optimising for the organisation's ability to keep operating safely as more and more (semi-)autonomous processes start making decisions inside it.
The agent you'd build for yourself and the agent you'd deploy in an agency aren't the same agent with a different tier of support. They are different artefacts solving different problems.
The conversation most organisations are having
I believe most organisations are somewhere in the middle of a conversation that goes roughly like this. A new class of assistant (Claude Cowork, Copilot Studio, Gemini agents, OpenClaw, whatever launches next) has matured to the point where a broad deployment looks genuinely attractive. A demo is given. Numbers are floated. A reasonable question surfaces: if these tools make individuals faster, and buying is cheaper and faster than building, why not procure them for every officer and move on?
The class keeps widening. Cowork handles scheduling, drafting, lightweight research. The newer tier of personal-AI tools reaches further: full desktop automation, multi-step workflows, longer-horizon agentic tasks on behalf of an individual user. Each generation is more capable and more appealing. Each also sharpens the same question rather than answering it: productivity for whom, measured how, and captured by what?
That question is a fair one, and the case for broad procurement is not weak. Individual productivity really does go up. The vendor takes on the cost of keeping up with a rapidly moving model landscape. Sanctioned access closes the shadow-AI gap that's already quietly open (officers are experimenting on personal accounts whether you've sanctioned it or not). Time-to-value is days, not quarters. Any platform team pitching an alternative path has to start by conceding that the buy conversation is doing real work.
The more important question, though, is a different one. Do the individual productivity gains become organisational outcomes? Or do they leak away before reaching anything that shows up at the level the organisation actually cares about?
We can also take a more cynical view of this - that in some organisations, the headline KPI for AI really is adoption (seats deployed, tokens consumed, vendor logos on the intranet, number of officers with a license). If that's the scorecard, broad procurement is already the right answer. This piece is written for a different audience: organisations whose real KPIs sit further downstream — case quality, policy outcomes, service reliability, citizen trust — and who want AI adoption to show up in those measures rather than only in the procurement count.
This is the gap DORA's chart is pointing at. It's worth looking at how the leak actually happens, because that's what a platform is built to address.
Why individual gains don't become organisational gains
Picture a staffer in a policy division. She gets Cowork. Within a week she's drafting faster than ever, putting together consultation summaries and first memos in a fraction of the time she used to. Her director notices. Her colleagues are curious. The deployment is working.
And yet, a year later, the ministry's delivery metrics may not show a meaningful change at the organisational level. DORA's work surfaces a few paths by which individual productivity gains from AI adoption fail to aggregate at the organisational level. Each is a real pattern, and each is specifically what a platform is built to address. It helps to trace our staffer's gains through some of them.
Friction doesn't go away. DORA finds that AI doesn't reduce friction; it shifts it. Our analyst's first drafts arrive twice as fast, but they also contain the occasional synthesised figure from a public report that looks correct but isn't, or the occasional cited case that turns out to be a plausible-sounding summary of something else. The time she saved on drafting is now spent spot-checking Cowork's output against original sources. On a personal workflow, that trade is usually worthwhile. On an organisational one, it depends entirely on whether the verification step is reliable. If every officer is verifying in their own private way, the organisation has no idea how much verified-vs-unverified output is flowing into its decisions.
What a platform does about it. Shared evaluation patterns, templated review gates for AI-produced artefacts, and observability so a second person can see what the first person's agent actually saw. The point isn't to slow anyone down; it's that "AI checked, human signed off" becomes a standardised step rather than a matter of personal conscience.
Quality debt is still there, but probably much less visible now. DORA 2025 shows throughput has flipped from negative to positive, but instability is still higher with AI. This means that while there is more output, there are also more things breaking per unit of output. A memo our staffer drafted is published. A month later, a downstream reviewer notices a cited precedent that doesn't actually exist. Nobody can reconstruct whether the error came from the staffer, from Cowork, from a misread of a real case, or from a synthesised abstract that looked plausible at the time. The cost of tracing a single incident balloons into a multi-day effort. The organisation absorbs it and moves on.
What a platform does about it. Audit trails and provenance tags so every output can be traced back to the agent, the prompt, and the sources it drew on. An internal memo's footnotes might even point to a Langfuse trace or to a citation the platform captured. This converts "something went wrong and nobody knows why" into "something went wrong and here's the root cause in under a minute". It provides the ability to explain after the fact, and prevent future occurrences.
Gains stay siloed. Someone in a different division has independently discovered that a particular prompt pattern produces consistently good consultation summaries. She shares it with her team, and a few of her colleagues start using it. Our first staffer never hears about it. Neither does the rest of the organisation. Both of them are, in effect, running parallel experiments that nobody is pooling results from. The organisation has paid for five hundred Cowork seats and is receiving one person's worth of compounding knowledge.
What a platform does about it. This is where platforms earn their keep. Shared context files (committed, versioned), shared skills and prompt packs, shared MCP servers, so that "a tool that synthesises across case precedents" is built once and used by every officer who needs it. Memory wrapped as MCP, so an agent spun up by officer B has the context that officer A's agent already learned. When our staffer's consultation-summary pattern is packaged as a platform skill, her fifty peers start using it within a week. Her discovery becomes the organisation's practice rather than her laptop's.
In short: Cowork on every officer's laptop produces individual gains reliably. Turning those individual gains into organisational outcomes requires a substrate that captures them, verifies them, and redistributes them. Without that, an organisation that spent heavily on AI tooling and one that didn't may look indistinguishable at the organisational level, even when every individual employee has genuinely got faster. That is what DORA's grey band is showing.
When you don't need this
That said, there are cases where the platform genuinely isn't needed.
If you are a one-man team drafting the occasional memo from public information, on your own laptop, signing off your own work, with no downstream dependencies on the output being correct, then Cowork is fine. You don't need a platform (or this article).
The platform becomes necessary when any of the following is true:
- AI needs to reach internal data that your existing access controls are supposed to gate
- AI output flows into decisions that affect other people, and those decisions need an audit trail
- The work spans domains or divisions, each with its own governance and its own systems of record
- You want the first person's learning to help the second person in a way that outlives either of them
- The organisation needs to answer "which agent did what, with which prompt, on whose behalf" after the fact
Another caveat: a small coding team can go surprisingly far with just a committed CLAUDE.md or AGENTS.md and a shared skills repo. Shared context-as-code covers a lot of the aggregation need when the work is code, the review process already exists, and the data at stake is the source tree you already audit through version control. Non-coding work doesn't get that shortcut. There isn't a git for policy drafting or case triage (I think?). When the work is consultation synthesis, procurement triage, ministerial briefings, or anything that touches internal records, the lightweight conventions that serve a coding team break down, and platform-level governance is what's left.
For most work inside an enterprise, at least one of those conditions is true. In government, almost all of them are true at once. That's why the platform conversation keeps returning to the same place: not "can we skip it?", but "how much of it do we need, and where do we start?"
So what actually is an "enterprise" agent?
The question isn't quite right, in my view. The more useful version is: what does an agent need to be embedded in to run safely in an enterprise?
The agent itself might be almost anything. Claude Code. An internal Python script. A Copilot session on a finance analyst's laptop. A Gemini agent drafting an HR policy. Again, the agent isn't what makes it enterprise-grade; the environment around it is.
In my view, an agent is enterprise-ready when all of the following are true of its environment:
- It has a scoped identity that isn't a person. When the agent acts, it does so as itself, not as a human who happened to be logged in. You can revoke it without firing anyone.
- Its context is versioned and owned. The prompts, rules, memory, and tool definitions that shape its behaviour are committed artefacts, not whatever happened to be in someone's clipboard.
- Its tool access goes through a governed surface. Internal APIs, knowledge bases, workflows, and services are reached through a layer that knows what it's allowed to touch, logs what it did, and can be updated centrally.
- Its actions are auditable. Every meaningful step it takes writes a trace to a place a human, a compliance review, or another agent can read.
- It's interchangeable at the model layer. If the model vendor changes, the agent doesn't die. The model is a dependency, not the whole stack.
- Somebody other than the builder runs it. It has a team, a runbook, a deployment pipeline, and works even without the builder present.
Every item on that list is a property of the environment the agent lives in, not of the agent itself. Pick any one of them and honestly ask whether your current AI deployments satisfy it. That's the audit.
So rather than calling it an "enterprise agent", maybe we should call it an "enterprise-ready environment". Which is what we'd usually call a platform.
The platform is the environment
The hard part of enterprise AI isn't the models. Everyone has access to the same models. The hard part is the boring layer everyone underinvests in: the shared, owned, governed substrate that every agent, every assistant, and every vendor tool eventually touches.
At our platform team we've been building roughly this:
- A central MCP gateway so every internal API, knowledge base, and workflow is exposed to agents through one governed surface. Teams publish, agents consume, the platform governs the middle.
- Agent runtime with sandboxed execution, right-sized compute, and proper lifecycle. Agents are workloads, not shell sessions on somebody's laptop.
- Agent identity so every agent has its own first-class identity with scoped credentials. When the agent acts, it acts as itself (no more "which engineer's token did the agent just use?").
- An Agent registry that provides a catalogue of available agents — visibility and access controlled, shareable, managed.
- Persistent agent memory, wrapped as MCP so the same context surface serves every agent regardless of vendor. The project-wiki pattern from the previous piece, at platform scale.
- Observability via OpenTelemetry piped into a central Langfuse, so every agent trace is queryable, auditable, and available to whatever eval harnesses you wire up in CI.
- A Skills platform where Agent Skills can be shared, versioned, evaluated, and evolved.
- A general-purpose agent as a first example, and a front door to agentic AI for government.
None of this is glamorous. Nobody gives a keynote on "we built a central MCP gateway". But this is what DORA's chart is pointing at, and what moves an organisation out of the grey band.
The more interesting part is that this platform doesn't only serve your coding agents. The same infrastructure serves a finance officer's Cowork session asking about invoices. It serves an HR assistant drafting policy. It serves the ministry portal's customer-facing chatbot. Every AI deployment in the organisation is a client of the same platform, which means every dollar invested in it compounds across every use case.
With the platform in place, a few things that were previously hard or impossible start to look routine:
- Cross-division workflows. When HR's MCP server, finance's MCP server, and IT's MCP server all sit behind one governed gateway with one identity model, an agent can span all three. "Onboard a new officer" becomes a single orchestration across three domains, instead of three separately-built integrations, each with its own auth flow, audit model, and squad maintaining it. (Imagine one place to talk to all your AIBots at once.)
- Long-running, cross-session agents. Personal assistants forget; context resets every session. A platform with managed memory and agent identity supports agents that persist for weeks: a grants-monitoring agent that tracks an application through its full lifecycle, a policy-tracking agent that watches cited acts for amendment over months, a procurement-review agent that holds context across a year-long evaluation. Those agents don't work safely on personal tooling, because the tokens expire, the context drifts, and the memory is ungoverned. They work on a platform.
- Sensitive-data work with audit defaults. A lot of analytical work on regulated data simply doesn't happen today, not because the analysis isn't valuable, but because nobody can answer "what did the AI see, what did it produce, who approved the output?" afterwards. With a platform, those questions have default answers (scoped identity, governed access, full traces). Work that was previously blocked by governance becomes tractable, under governance.
None of the above needs a huge platform team (only in the beginning, don't cut my MMF). It needs the pieces to exist. That's the point.
Minimum viable platform
A smaller organisation reading this might reasonably feel the argument only applies to places with fifty-person platform teams and custom AgentCore deployments. That isn't the argument, and it shouldn't land that way.
The minimum useful platform is much smaller than what a large enterprise would build:
- One MCP gateway. Doesn't have to be a managed service. A lightweight self-hosted gateway in front of a small set of internal tools is enough to get scope control, logging, and a single integration surface.
- One identity model for agents. Scoped service accounts from your existing identity provider (e.g. Entra ID, Okta) work fine. Agents get their own identities, even if those identities are just distinct rows in your IdP rather than a new system.
- One trace sink. Open-source Langfuse, OpenTelemetry into a shared observability stack, even structured logs landing in a central store. The requirement is "queryable after the fact", not "bespoke observability platform".
- One context convention. A committed location for
CLAUDE.md/AGENTS.md/ skill files, reviewed through the same pull-request process as any other code. No new tooling required; the existing code review process is the governance.
That is the MVP. Four pieces, each small, each extendable. What matters is that each piece exists, not that each piece is gold-plated. The platform matures as the need matures, much the same way the bash-script harness in the previous piece did.
Skills need SDLC too
The buy-it-off-the-shelf conversation turns up in a subtler form when Skills (and their equivalents) enter the picture. Anthropic ships Skills. Peer vendors ship their own flavours. The pitch is appealing: a shared library of packaged capabilities (e.g. "draft a consultation summary", "triage a tender submission", "extract action items from a transcript") that every assistant in the organisation can pull from.
A skill library is useful. A skill library alone, however, is not enough.
Skills are software. They have inputs, outputs, failure modes, and real effects on the humans who use them. Once you treat them as software, the same questions you would ask of any other production software appear:
- Provenance. Which version of which skill ran on which task, submitted by whom, approved by whom, drawing on which sources?
- Versioning. When a skill changes, does work done under the old version remain reproducible? Is there a rollback path when a new version misbehaves?
- Evaluation. Does the skill produce the outcomes its author claims (consistently, over time, across users)? Do the evals run automatically when the skill changes?
- Auditability. When an output turns out wrong, can the trace be reconstructed in minutes rather than days?
- Composability. Can this skill be used inside another skill? Are dependencies tracked?
- Security review. Skills are software with code-execution privileges. Treat installing a Skill with the same rigour as installing software on a production system.
- Coexistence and recall. Skills compete for the agent's attention. Adding the two-hundredth skill can quietly degrade the first by stealing its triggers or crowding the model's working set (Anthropic caps it at eight Skills per request for a reason).
A skill library that only stores skill files gives you, at best, one or two of those. A platform that treats skills as first-class artefacts gives you the rest: shipping them through a proper SDLC, running evals before promotion, versioning them, tagging their provenance, surfacing usage metrics. Same argument as earlier, one level deeper. The skill is the artefact. The platform is what makes the artefact trustworthy at scale.
When our staffer's consultation-summary prompt becomes a platform skill, this is what it passes through: evals before the first peer uses it, a version tag, usage telemetry, and feedback loops from reviewers who catch mistakes. The skill's lifecycle starts to look more like software than like a markdown file in a shared drive, which is the point.
Control vs dependence, or why not just buy
Back to the broad-procurement question. A stronger version of it is worth taking seriously: why build anything at all? The assistants really are getting better. Anthropic ships Claude Enterprise. Microsoft has Copilot. OpenAI has its enterprise offerings. Google has Gemini Enterprise. Pay the vendor, give officers access, move on.
Sau Sheong wrote a piece recently called "From Buy vs Build to Control vs Dependence" that reframes this conversation. The old buy-vs-build question was about cost and speed. The new control-vs-dependence question is about whether you can still function when the vendor changes the terms.
He gave a handful of examples. Broadcom absorbs VMware, and some European cloud providers see price increases of between 800 and 1,500 per cent. Oracle changes Java licensing from usage-based to headcount-based, and an enterprise with a handful of developers writing Java suddenly owes roughly 90,000 dollars a year. An ICC prosecutor gets locked out of Microsoft email and has to migrate to open-source infrastructure. Russian banks lose SAP access overnight after the Ukraine invasion.
None of those were technology failures. They were dependency failures, and the extent of the dependency determined the cost of change.
Sau Sheong's recommendation is layered: buy the commodity, build the layer that encodes your workflow, your compliance model, your customer experience. For governments specifically, he puts it more sharply: "Own the interfaces. The APIs, the data schemas, the identity layer, the integration standards."
That quote is, effectively, a description of what your platform should be.
If your organisation treats AI as a pure buy-decision, every vendor outage, price hike, or geopolitical wobble hits you at full force. If your organisation's only answer to AI is "we bought Claude Enterprise", then the day Claude's terms change, you have no fallback. No shared context survives the migration. No shared memory carries over. No audit trail maintains continuity. Every team starts a greenfield integration with whatever comes next.
If you own the platform, the assistants are clients. Clients are replaceable. The platform doesn't have to be.
This isn't an argument against buying — these vendors build great products and you should use them. It's an argument against buying only. The buy-decision and the build-decision aren't alternatives. They are different layers of the same stack.
The flavour-of-the-month problem
A lot of enterprise AI strategies are, if you squint, a series of reactive purchases to whichever assistant category is hot that quarter. That strategy produces a particular pattern: your organisation ends up with four or five active assistants, each integrated separately to a handful of internal systems, each with its own rules-file conventions, its own audit trails, its own identity model. None of them share context. None of them share memory. When one gets retired, the integrations around it are abandoned code.
The control-vs-dependence reframing says this is backwards. The question isn't which assistant is best this quarter. The question is: what part of your AI stack are you willing to let vendors own, and what part must you own yourself?
Answering that forces a layered view:
- The model layer is commodity. Buy it. Pick whoever's best this quarter.
- The assistant layer is commodity-with-taste. Different teams will prefer different tools; let them.
- The integration layer (MCP servers, identity, memory, audit, policy) is yours. Build it. Own it. Make sure every assistant in the organisation consumes from it.
If you get that layering right, flavour-of-the-month becomes a feature, not a bug. Your teams pick whatever assistant fits their taste; the platform makes their choice safe. Tomorrow's hot new agent is a day-one citizen, because it talks to the same MCP gateway, authenticates through the same identity layer, and writes traces into the same observability substrate as everything that came before.
That is a very different procurement posture from "we bought Copilot".
The mandate expansion
"AI development" in 2026 isn't just developers using AI to write code. It's the organisation shipping AI to every kind of user it has — engineers, analysts, policy officers, service officers, and the public. Every Cowork session on a finance officer's machine is an AI deployment. Every GenAI feature in a ministry portal is an AI deployment. Every agent automating a workflow between two internal systems is an AI deployment.
From the platform team's seat, all of that ends up being the same kind of problem. Scoped identity. Governed data access. Audit trails. Memory. Context discipline. Policy enforcement. It is the same substrate underneath.
The work has expanded faster than the mandate has. Most platform teams are still answering "why do we need you?" from leadership that recently signed a large Cowork contract. The honest answer isn't that platform teams claimed a bigger mandate; it's that the scope of what the organisation is trying to do with AI expanded, and every new deployment quietly started building on top of what the platform is supposed to provide, whether anyone named it that way at the start. The scope arrived. The mandate gets earned, deployment by deployment.
What this all comes back to
At the enterprise level, the harness isn't yours to own alone.
The most useful thing a platform team can bring to the broad-procurement conversation isn't a counter-proposal. It's a yes, and. Yes, buy Cowork. Give it to every officer who can use it. And build the platform underneath, so the individual gains those officers produce aggregate into something the organisation can actually feel. Without the "and", Cowork is a productivity tool on five hundred laptops. With the "and", it's an organisation that compounds.
My guess: by the end of 2027, organisations without an internal AI platform will end up paying for AI twice. Once for the assistant licences, and again for the integrations they keep rebuilding every time the assistant of choice changes. The ones that took the platform layer seriously early will probably look, in hindsight, a lot like the orgs that took cloud seriously around 2015, versus the ones that just bought a few VMs and stopped there.
At individual scale: build your harness, own your harness, evolve your harness. At enterprise scale: build the layer that lets everyone else have one.
The model is the engine. The context is the fuel. The harness is the vehicle. The platform is the road.
You need all four. At enterprise scale, nobody travels unless you pave the road.

(Yes, I'm aware this is technically an OFF-ROAD buggy)