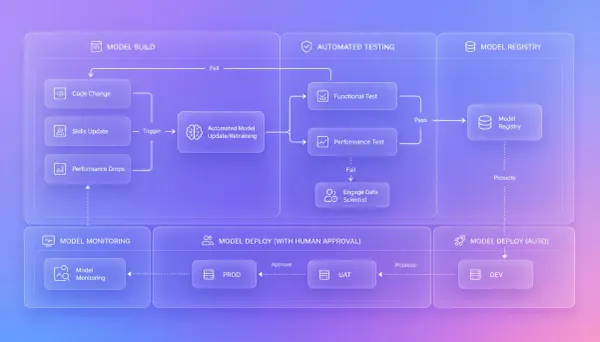
The Studio MLOps Transformation: Moving from Stage 0 to Stage 3 (Part II) A maturity roadmap and a cultural shift. Machine Learning
The Studio Building MLOps Bridges: Our Journey in Uplifting Agencies A practical guide to MLOps adoption across Government teams. Machine Learning
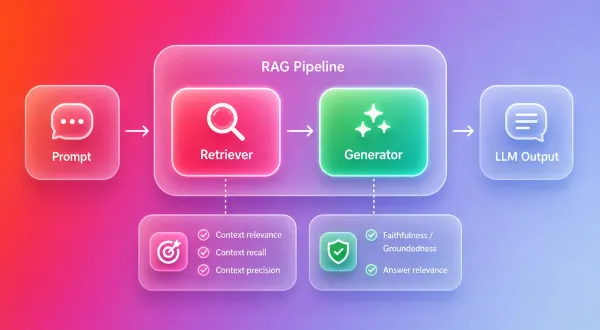
The Studio Building a Better RAG Pipeline for HR Policy Q&A: What Worked and What Didn’t We tested the most effective approaches. LLMs
“The Bots Are Here. Now What?” How Knowledge Management Became the Key to Powering GenAI Solutions Available LLMs are powerful enough. What we are missing is the knowledge to fuel them. General
Does your LLM know when to say “I don’t know”? Refusal by a model to answer may sometimes be more valuable. Responsible AI
Fine-Tuning Language Models for Long-Context Data: Automated Stance Analysis of Citizen Discussions Addressing technical challenges of processing high-volume public feedback for policy-making Responsible AI
MLOps Transformation: Moving from Stage 0 to Stage 3 (Part I) Much a cultural shift as a technical one. Machine Learning
Evaluating MOE’s SLS Learning Assistant: Using Synthetic Data and LLMs to Benchmark Faithfulness and Factuality Safer, faster testing of student-facing AI before real-world deployment. General
From Infrastructure to Intelligence (Part 1): Strategic Foundations for AI Model Hosting and Agent-Based Architectures on the Cloud What began as simple chatbot prototypes has evolved into full-fledged agent architectures. Infrastructure
The Lab (Part 2) LLM Safety Alignment for the Singapore Context using Supervised Fine-tuning and RLHF-based Methods Safety must be "baked in". Responsible AI
The Lab (Part 1) LLM Safety Alignment for the Singapore Context using Supervised Fine-tuning and RLHF-based Methods The process of "teaching" models to be safe Responsible AI
The Lab Eliciting Toxic Singlish from r1 A red-teaming exercise that proves even "reasoning" models can be coaxed. Responsible AI