Stress-Testing Government Communications with AI Personas Grounded in Real Voices
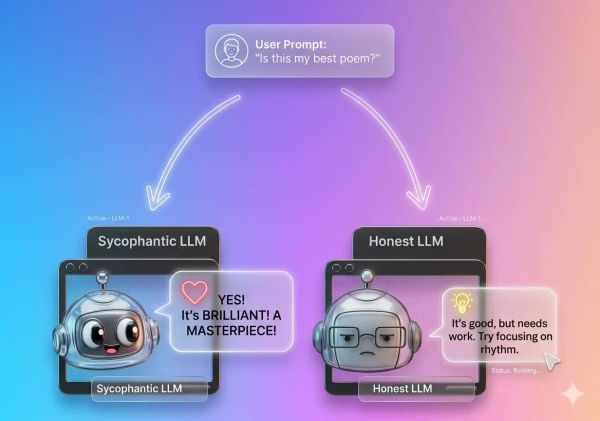
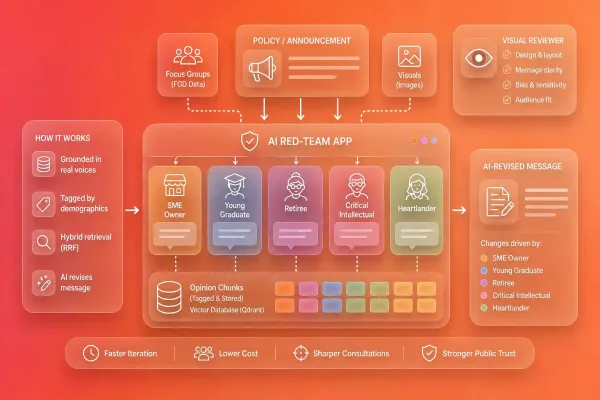
Government communications can misfire in ways their authors never intended. We built an app that lets officers stress-test drafts against AI personas grounded in real Singapore voices, so they can catch what they missed in minutes rather than weeks.