Validating Annotation Agreement between Humans and LLMs
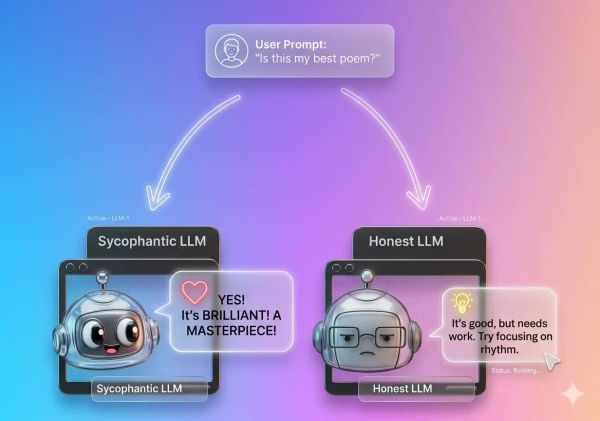
Who Judges the Judge?
At GovTech’s AI Practice, we’ve been embracing what’s known as “LLM-as-a-judge” — essentially employing LLMs as evaluators across our AI workflows. This approach has become one powerful approach in our evaluation toolkit.
We use LLMs extensively across multiple areas: judging other