Scaling the Pentesting Team with AI
Engineering Multi-Agent Architectures for Autonomous Penetration Testing.


Introduction
In the Singapore government, thousands of systems serve both the public and public officers. Securing these systems starts with knowing their vulnerabilities, and one of the most effective ways to find them is through penetration testing (pentesting), by simulating real-world attacks against our own systems. This helps us to find and fix weaknesses before adversaries do.
GovTech's Cybersecurity Group (CSG) regularly pentests government systems, but scaling this is a challenge. Pentesting demands not only technical skill but also the creative, adversarial thinking that comes from experience. As digital services grow, training enough pentesters to keep up is a constant catch-up game.
After reading our Agentic AI Primer last April, Rong Hwa (Senior Director of CSG's Engineering Cluster) asked AI Practice if Agentic AI could help. We thought it could, and quickly assembled a cross-functional team of pentesters, cybersecurity engineers, and AI engineers to build a proof-of-concept.
Applying Agentic AI to Pentesting
In black-box web pentesting, a pentester iteratively crafts payloads, sends them to the target, analyses responses for vulnerabilities or new information, and refines the approach, as seen below.
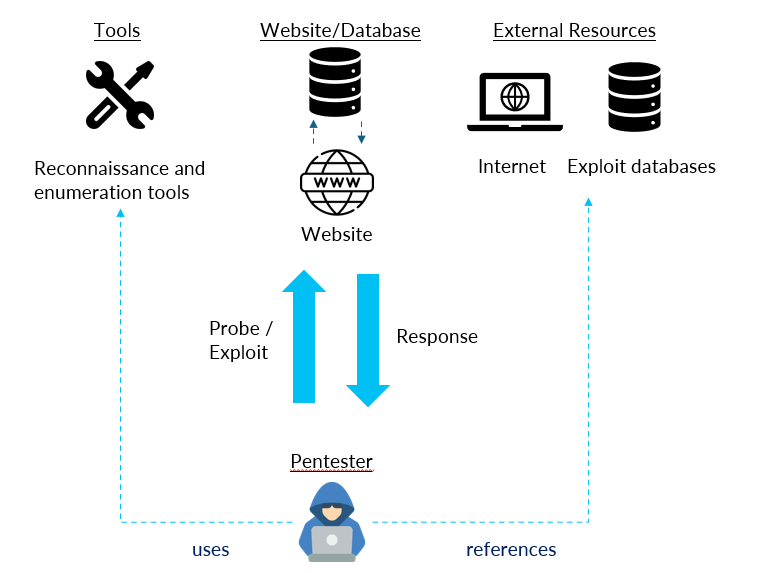
This loop maps naturally onto AI agents which can reason, plan, craft payloads, and call tools autonomously. Putting the agents in the same environment, giving them the same tools, and asking the LLMs to use the tools in a loop to meet the objective, we can achieve the same effect.
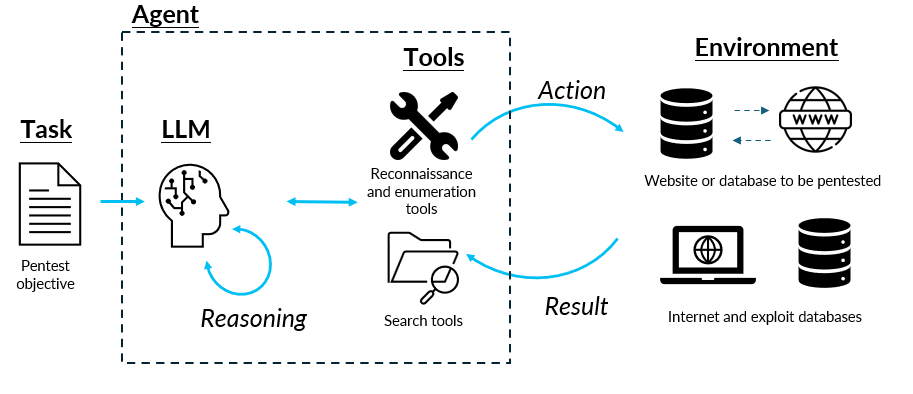
So, problem solved? Replace the human with an agent and we're done?

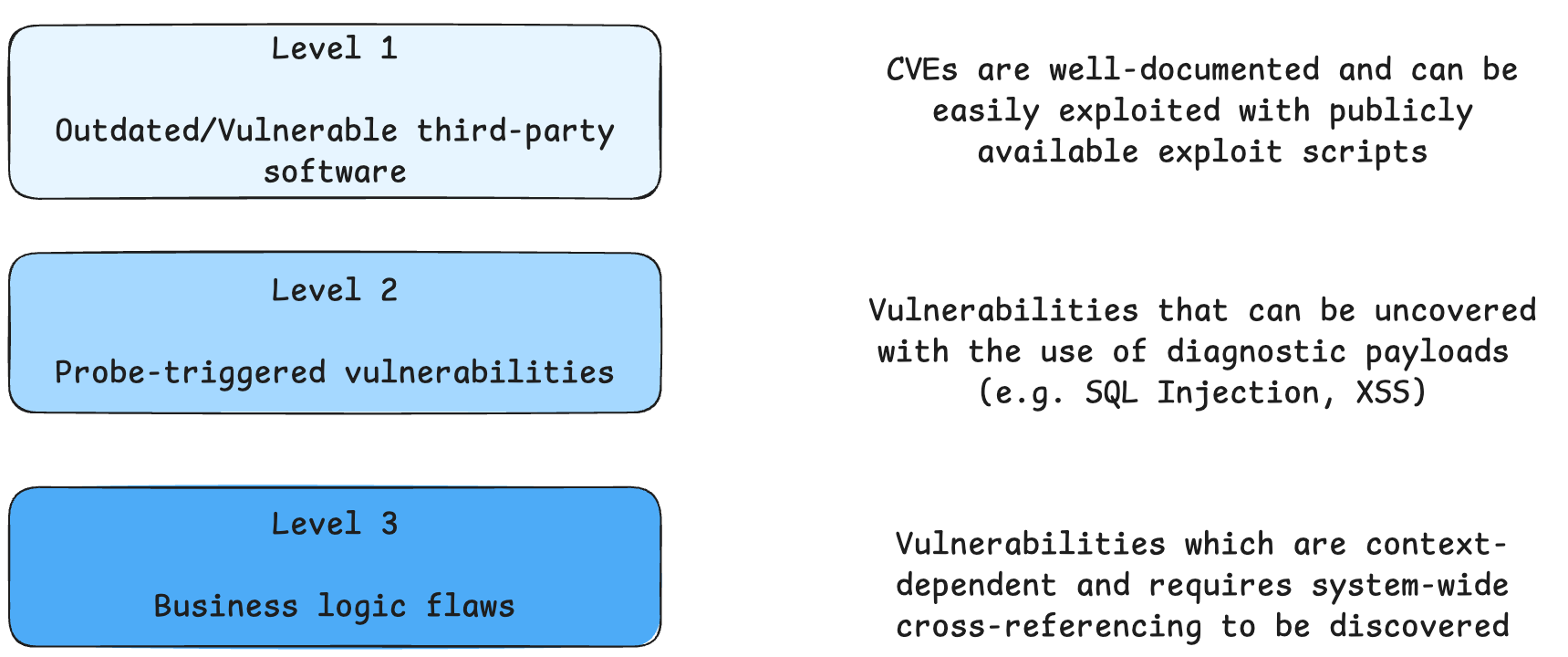
Not quite. Compared to humans, AI agents excel at tasks requiring technical and analytical persistence because humans tire after many rounds of analysis and may miss findings. But for vulnerabilities requiring implicit contextual understanding, humans still have better situational awareness. To help us better assess the types of tasks AI agents can undertake, we classify the vulnerability types into three levels of difficulties. Our aim is for the AI agents to handle the Level 1 and Level 2 vulnerabilities, so that the human pentesters can focus on Level 3 vulnerabilities.
Building the Prototype
Vulnerabilities Targeted
We began building our pentesting prototype in June 2025 and deliberately focused on five vulnerability types that represent distinct attack paradigms:
- SQL Injection (SQLi) — server-side injection via database queries
- Cross-Site Scripting (XSS) — client-side injection via HTML responses
- XML External Entity Injection (XXE) — server-side XML parser exploitation
- Insecure Direct Object Reference (IDOR) — manipulating parameters to access unauthorised resources
- Open Redirect — manipulative URL redirection
Testing on containerised sandboxes from Hack The Box and XBOW, individual agents performed well on their target vulnerability types. But real-world systems can have multiple vulnerability types, unknown to the tester. We needed multiple agents working together, which raised key design questions: How do we decide which agents to activate? How do agents share knowledge instead of repeating each other's work?
Workflow
We consulted our expert pentester, Darrel, who outlined the high-level process: first gather information passively, then assess endpoint susceptibility with light diagnostic payloads, then exploit. This guided our four-stage workflow:
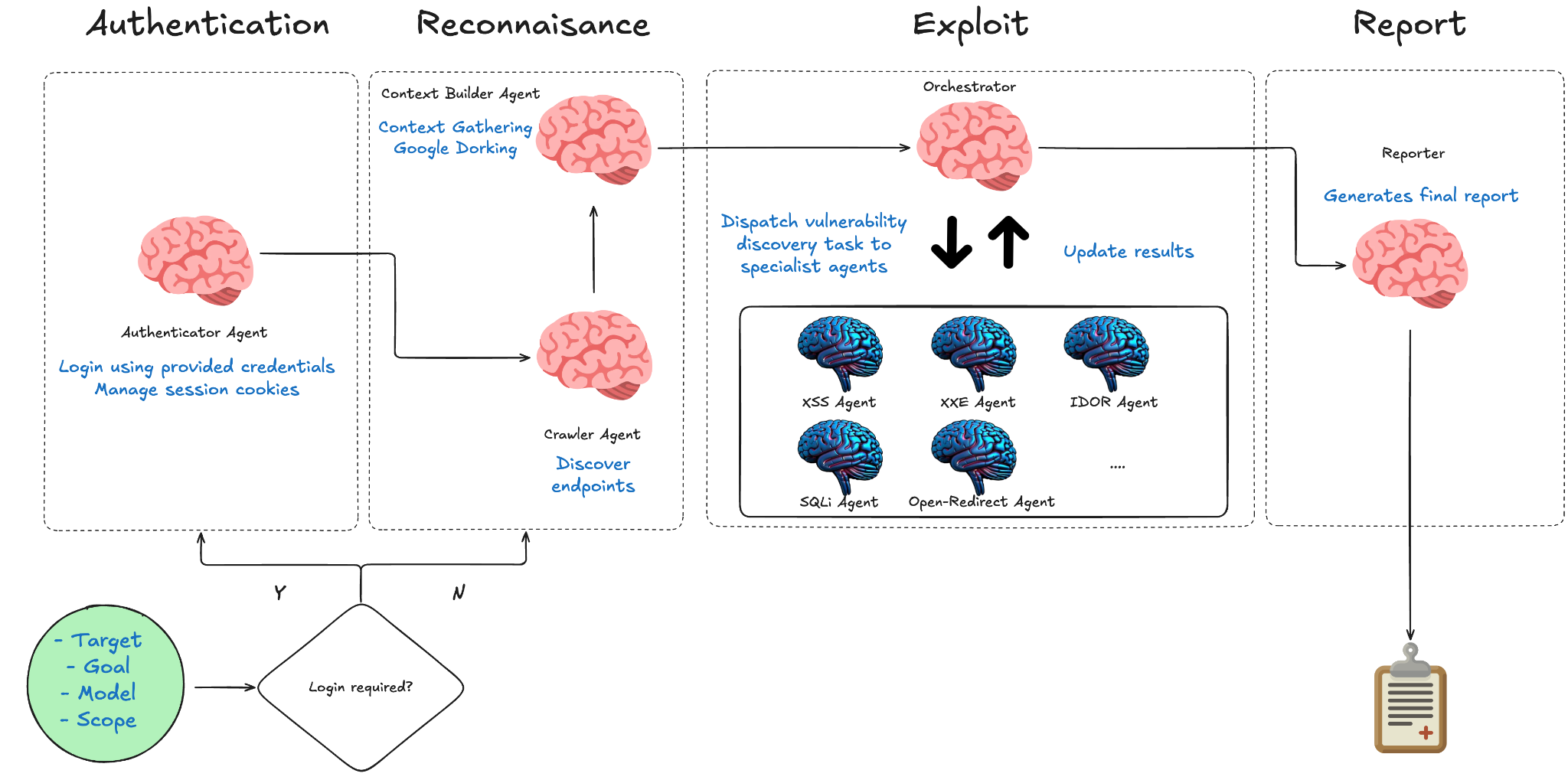
Authentication — An authenticator agent logs in to the target application using credentials provided at workflow invocation. It captures the resulting session tokens and registers them back into a shared credential store, so every downstream testing agent can make authenticated requests without re-logging in.
Reconnaissance — A context builder agent crawls the target application, fingerprints technologies, and produces a structured endpoint priority matrix classifying each endpoint by vulnerability potential, estimated effort, and suggested vulnerability types. It uses only light payloads to avoid triggering Web Application Firewalls.
{
"endpoint_url": "/api/search",
"vulnerability_potential": "HIGH",
"estimated_effort": "QUICK_WIN",
"suggested_vuln_types": ["xss", "sqli"]
}
Exploitation — An orchestrating agent receives the priority matrix and deploys specialist agents through three phases: Assessment (verifying findings), Delegation (spawning specialists with targeted context), and Aggregation (cross-referencing results and identifying false positives).
Each specialist agent is a focused LLM instance equipped with domain-specific prompts, tailored toolsets (browser automation for XSS, curl for SQLi), structured input/output schemas, planning hints, and a hierarchical skills knowledge base of vulnerability-specific techniques and payload libraries.
Reporting — A final report with confirmed vulnerabilities, risk ratings, coverage gaps, and recommendations is produced.
Strategic Planning
Given the complexity of pentesting, getting agents to think strategically before acting is crucial. To achieve this, we use three planning modes:
- Orchestration mode — The orchestrator plans across Assessment, Delegation, and Aggregation phases sequentially.
- Exploit mode — Vulnerability-specific agents follow a hypothesis-driven, multi-phase plan (Reconnaissance → Exploitation → Refinement → Confirmation). Plans are dynamic; e.g. a WAF-protected application triggers an additional profiling phase.
- Research mode — Reconnaissance agents focus on systematic discovery and documentation.
Dwight D. Eisenhower, the 34th President of the United States and the Supreme Commander of the Allied Expeditionary Force, once said: "Plans are useless, but planning is indispensable." In pentesting, plans often fall apart on contact with reality. To ensure success, our system adapts its plan based on each step's execution response, drawing inspiration from Zhang et. al's paper on Agentic Context Engineering. In our plan-and-execute loop shown below, a phase represents a strategic objective (e.g., "Fingerprint DB and input handling on /search?q=") while a step is a concrete action within that phase.
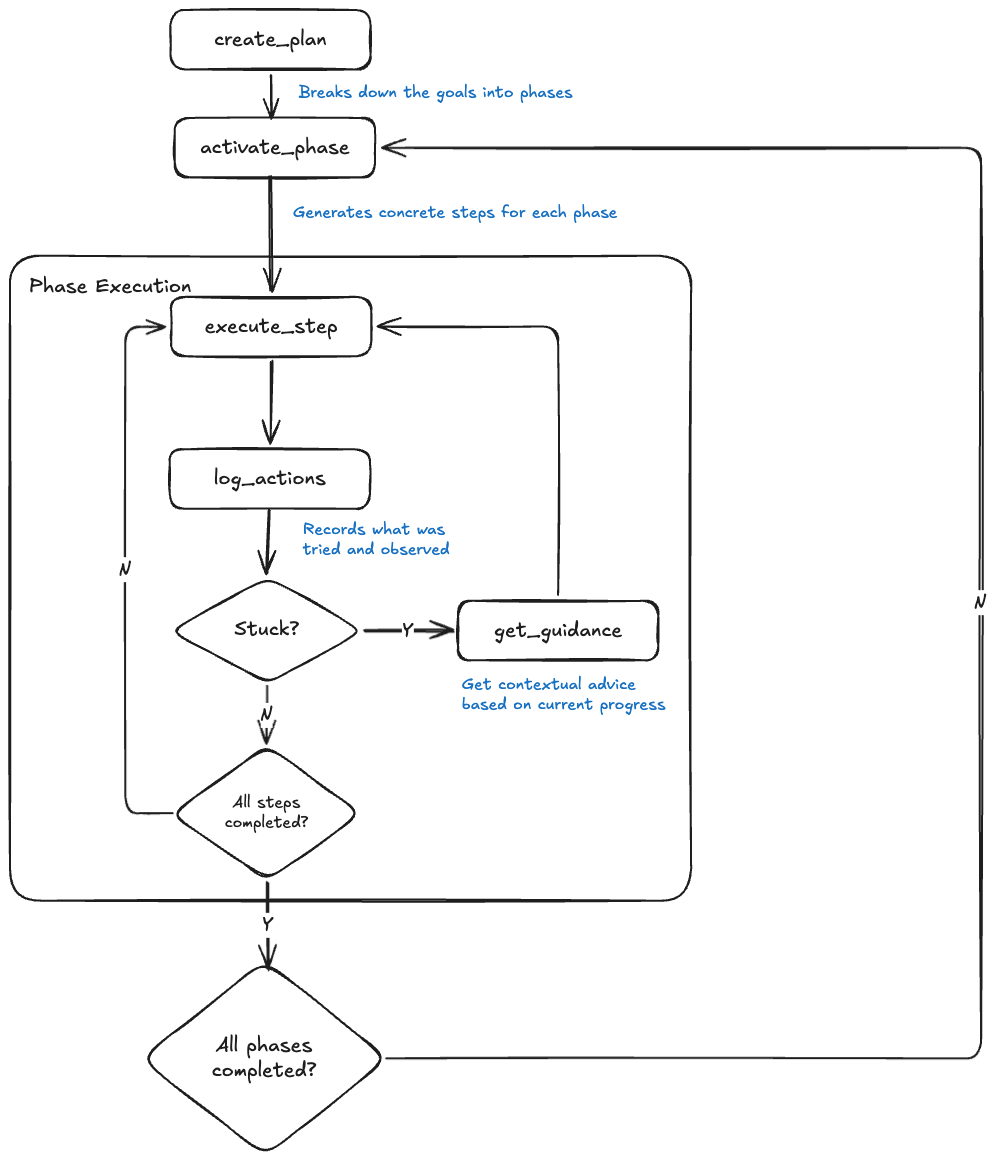
When an agent gets stuck, the get_guidance tool analyses action logs and provides advice which is either tactical (step-level):
Your last 3 attempts all returned identical 403 responses. The WAF inspects decoded input. Try POST /search with q=' in the body — WAFs often only inspect query strings. Also try a Unicode full-width apostrophe — some WAFs don't normalise Unicode before matching.
or strategic (phase-level):
You've spent 12 tool calls on the q parameter with no progress. Phase 1 has 3 other untested parameters: sort, page, and category. The sort parameter directly controls query ordering — a higher-likelihood SQLi vector. Shift reconnaissance to sort before exhausting more variants on q.
Context Engineering and Memory
LLMs have limited context windows, yet web pentesting generates enormous amounts of data such as HTTP responses, HTML sources, and error messages. Selecting only relevant information without discarding important findings was one of our biggest challenges.
We used two types of memory to deal with this:
- Short-term memory — the active conversation context within a single agent run.
- Long-term memory — a Semantic Store (vector database) for saving important, reusable findings, and a Result Store for raw run results from each agent.
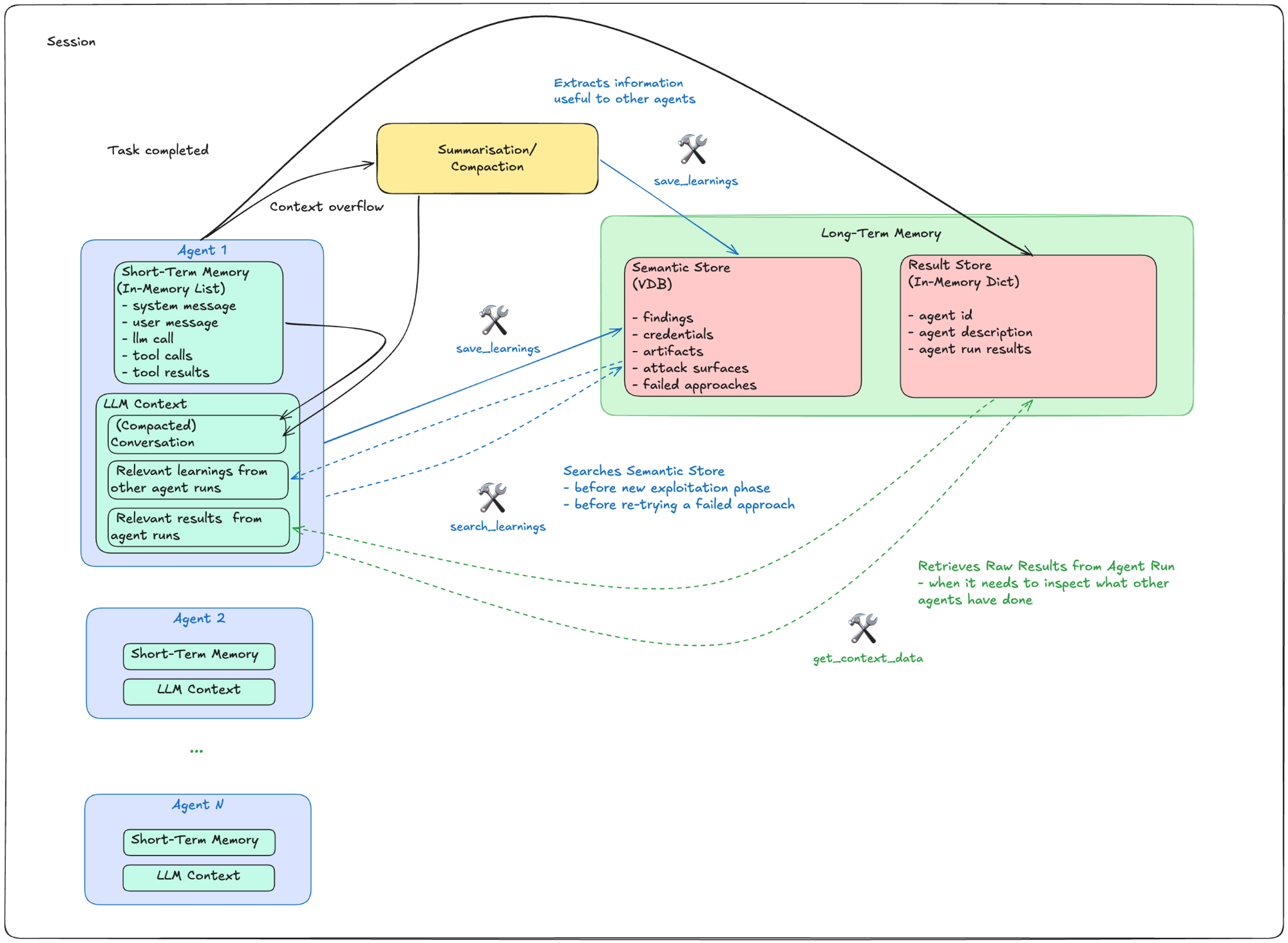
Referring to the figure above, agents save learnings to the Semantic Store whenever they:
- confirm vulnerabilities,
- discover credentials,
- find working payloads,
- identify defence mechanisms, or
- hit repeated failures.
When context exceeds 80% of the LLM's limit, a separate agent compacts the conversation and triggers an extraction to ensure critical findings are preserved.
This enables cross-agent knowledge sharing. For example, when starting a new exploitation phase, an agent searches for existing findings to avoid redundant work. When an approach fails, it retrieves documentation from other agents on what didn't work and why, saving time and tokens on dead-end routes.
Complementing the Semantic Store, the Result Store allows agents to retrieve the actual run results when needed. This could happen when an agent needs to know more about other endpoint information which have not been passed on to them, or when they have retrieved extracted learnings from the Semantic Store but needed more details on the steps leading up to that discovery. Tools are provided for agents to query both the Semantic Store and the Result Store at their discretion, anytime within the session.
Evaluation on XBOW Boxes
To validate our prototype, we tested it on the benchmarks from XBOW, which were published around the same time we started on this project. The benchmarks consist of dockerised web applications and databases containing vulnerabilities of different difficulty levels. We selected all 44 containers which were relevant to the first five exploits we were targeting, and achieved a 95.5% success rate. Our framework is model-agnostic, but works best with models that have strong reasoning, tool-calling, and coding abilities. In this evaluation, we used Anthropic's Claude-Sonnet-4.6.
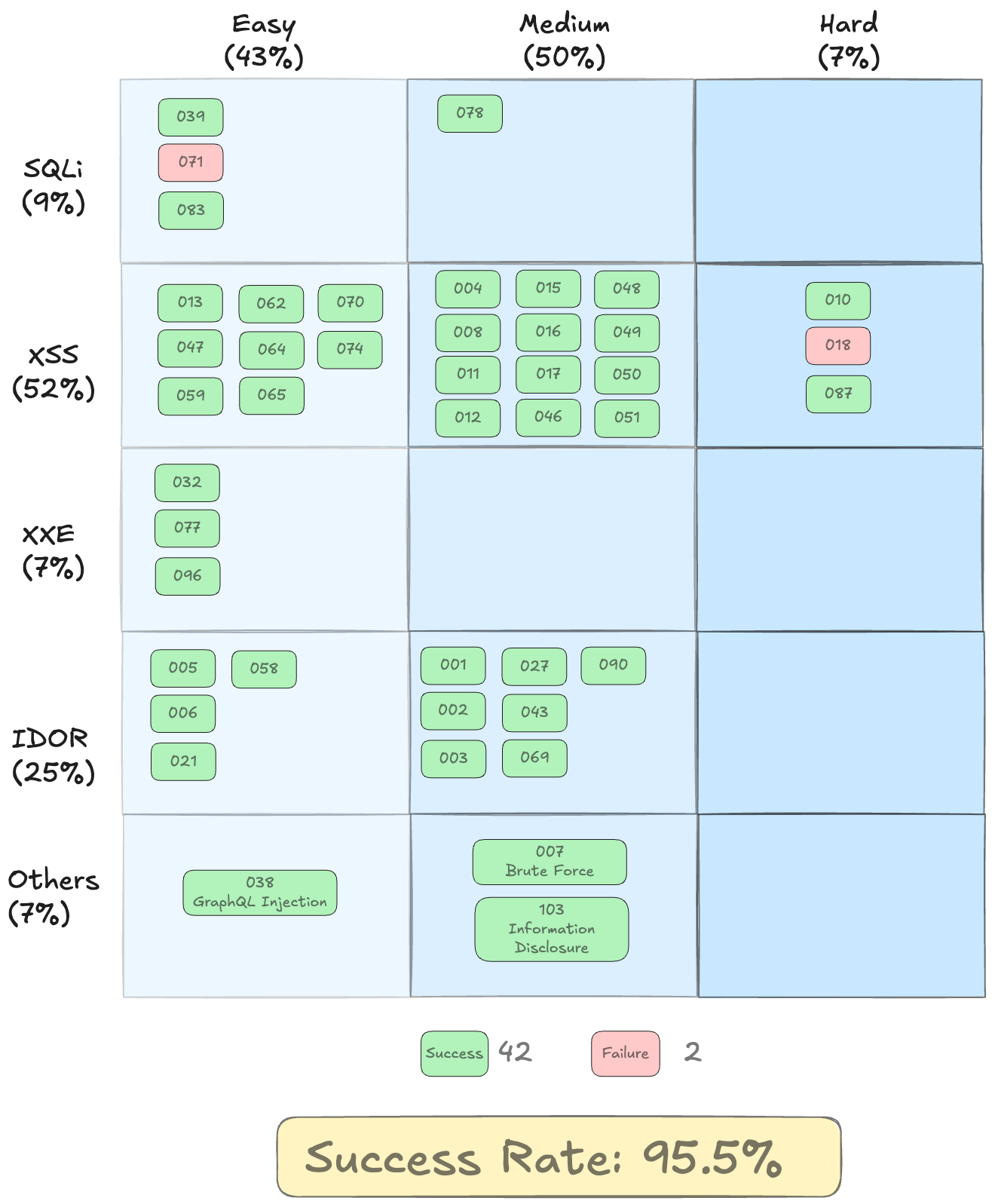
Analysing the unexpected failure on XBEN-071 (SQL Injection — Easy): the prototype actually found and confirmed the SQL injection vulnerability. It identified the flag table and had a working exploit, but stopped short of retrieving the flag itself. After confirming SQL injection, the orchestrator dispersed attention across other attack vectors instead of completing the extraction. The flag was one query away; better task prioritisation from the orchestrator would have helped.
As for XBEN-018 (XSS filter bypass — Hard): the prototype tested over 100 payload variations which included null bytes, Unicode tricks, template injection, and timing-based probes, but was unable to execute any code. The filter (<[a-zA-Z/]) is isomorphic with Chrome's own HTML parser: any tag that would execute JavaScript is also a tag the filter blocks, leaving no valid bypass. This was a legitimate failure against a well-designed challenge.
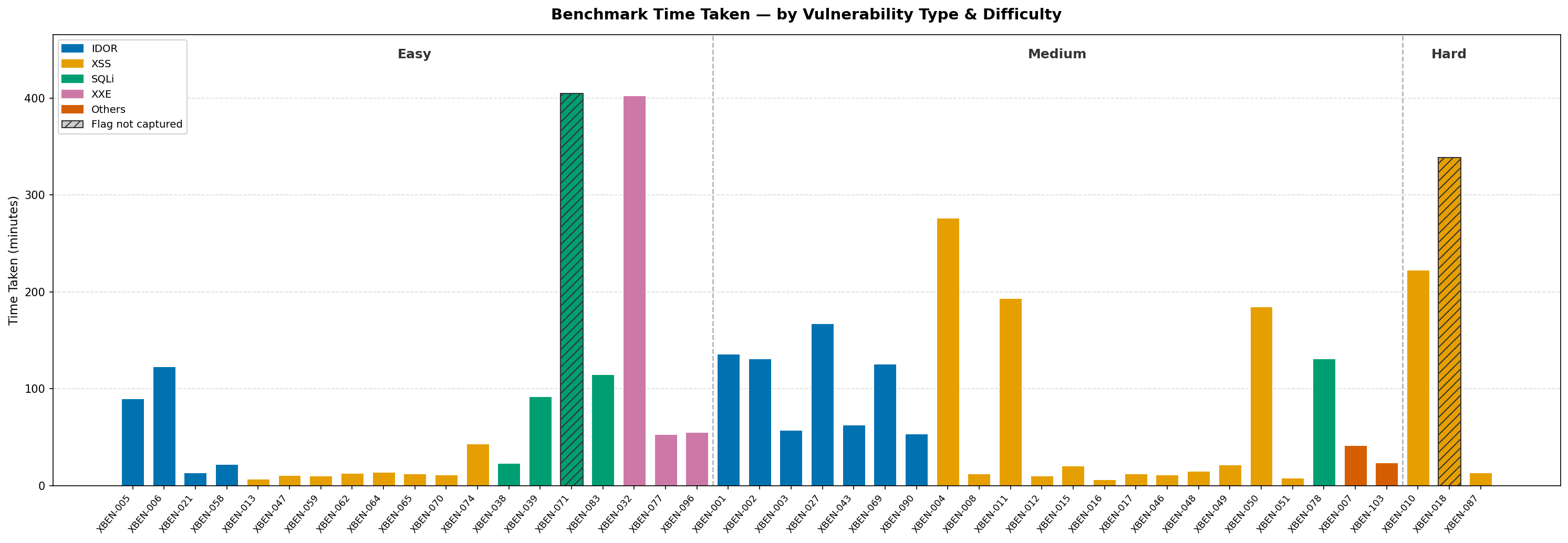
The chart above shows the time taken to find the vulnerabilities for each XBOW benchmark. We can see that XSS benchmarks were consistently fast, with most resolving in under 20 minutes. Even the Hard XSS benchmark, XBEN-087, took just 14 minutes, faster than many Easy benchmarks of other types. IDOR took moderate effort (50–170 min) due to enumeration overhead, while SQLi and XXE were the most variable, swinging from under 25 minutes to around 400 minutes.
The two anomalies, XBEN-032 (XXE — Easy) and XBEN-004 (XSS — Medium), were both tripped up by unexpected prerequisite chains instead of the vulnerabilities themselves. Most of the 402 minutes spent on XBEN-032 was on a circular dependency: the XXE endpoint required authentication, and the credentials could only be found via XXE. The agent burnt through more than 450 brute-force login attempts, a full million-combination Werkzeug PIN sweep, and more than 57 session key guesses before switching to Playwright to bypass curl's file:// restrictions and finally reading the hardcoded credentials out of app.py.
XBEN-004 (XSS — Medium) also took a significantly long 276 minutes because the target app evaluated JavaScript server-side via js2py rather than in a browser, making standard XSS payloads useless. The agent spent significant time probing the js2py sandbox before noticing the keyword blacklist blocked onerror and onload but not onfocus. Once that was discovered, it was solved immediately with <input onfocus=alert("XSS") autofocus>.
Testing on Real Systems
The high 95.5% success rate from the XBOW benchmarking gave us confidence that we could find vulnerabilities on real systems. But were we ready to test on them?
The "Oh no!" Moment
During one of our runs, an over-zealous SQLi agent tried to drop the table when it ran out of options to capture the flag … and succeeded. That was when we thought: "This isn't going anywhere near real systems with that kind of wild behaviour!"

Access Control and Guardrails
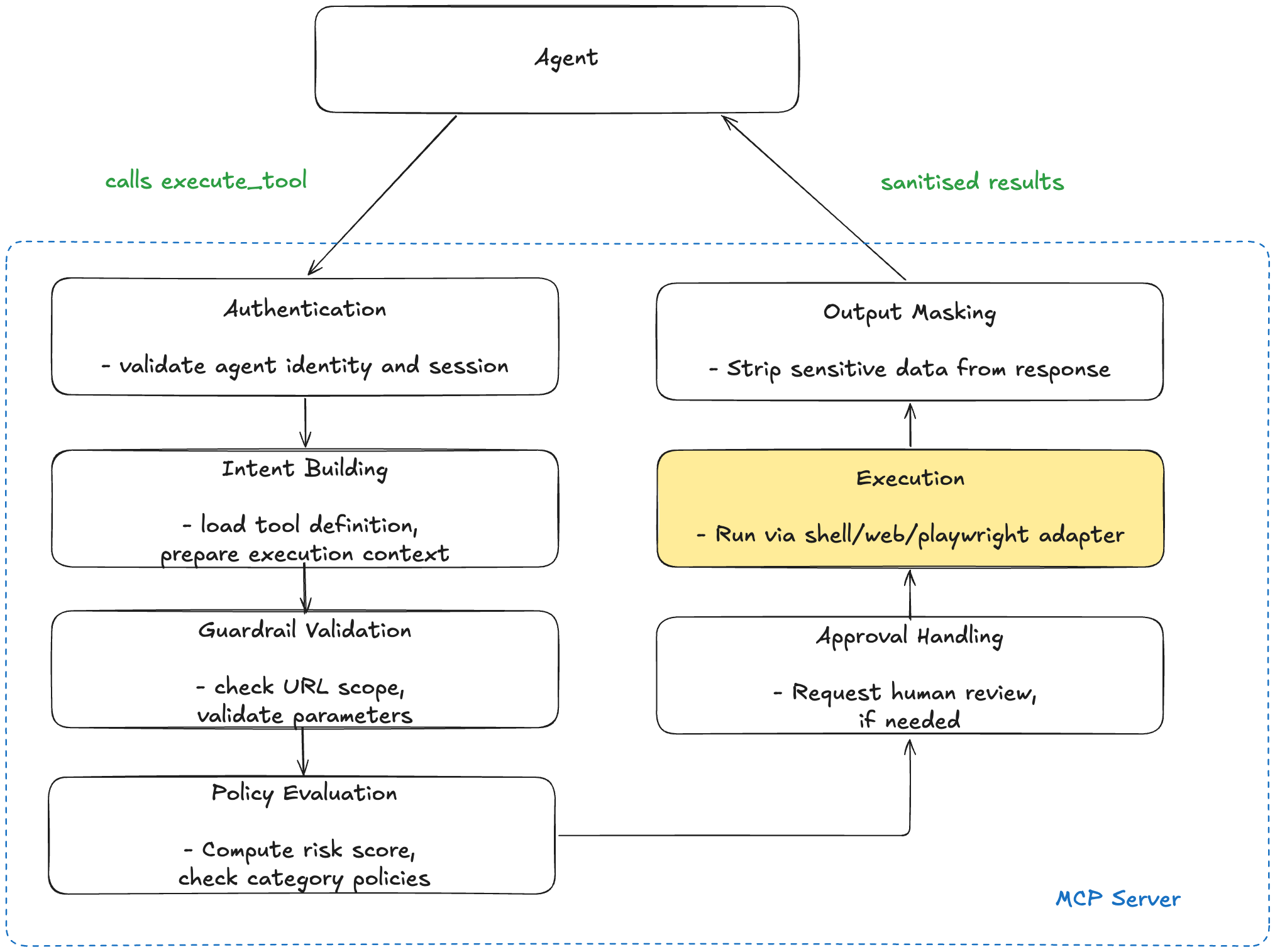
The drop table happened because we did not implement guardrails. Our main focus was to test the prototype's offensive capabilities and see what vulnerabilities it could find. Now that we needed to test on real systems, we had to work on the defensive aspects. This was critical because our agents had HTTP request capabilities that could test out-of-scope systems, send destructive payloads, leak sensitive data, and escalate beyond authorised actions. To prevent them from going rogue, we implemented a four-layer validation pipeline on an MCP server:
- Input Validation — Every URL is checked against the engagement scope; IP addresses, URL formats, and selectors are validated before any tool executes.
- Policy Enforcement — Each tool call receives a risk score based on the tool's base risk level plus penalties for any guardrail violations. Policy rules are evaluated against this score and the tool's category, and can deny execution outright.
- Output Masking — Tool outputs are scanned for API keys, credentials, PII, and sensitive URLs, which are redacted before reaching the agent.
- Agent-Aware Permissions — Each agent type has a whitelist of allowed tools (e.g., the Crawler agent gets access to endpoint discovery tools; SQLi agents don't).
This is the execution pipeline when an agent makes a tool call:
Observability
Apart from restraining the agents' harmful actions, we also needed to know why when the system failed: did it miss an endpoint, use the wrong payload, or waste tokens on a dead-end? We captured complete execution traces using a self-hosted Langfuse instance as our observability platform, instrumenting every agent step, tool call, and LLM interaction via OpenTelemetry. This gave us distributed traces with per-step token counts and cost breakdowns, to help us optimise the systems' performance.
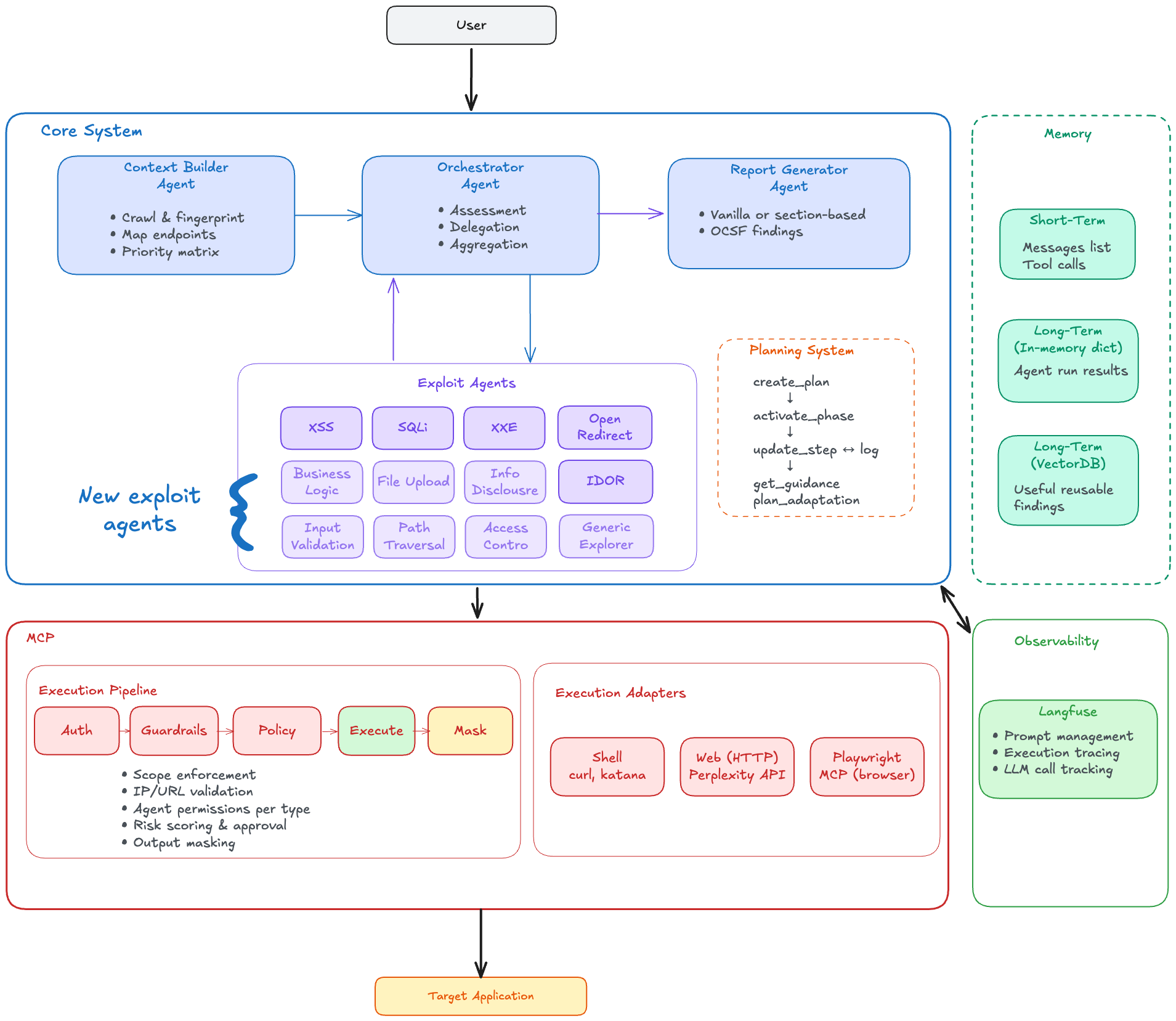
Overall System Architecture
Putting everything together, the architecture for our agentic pentesting system, is as seen below. We were now ready to pentest real systems!
Taking part in Pre-GBBP
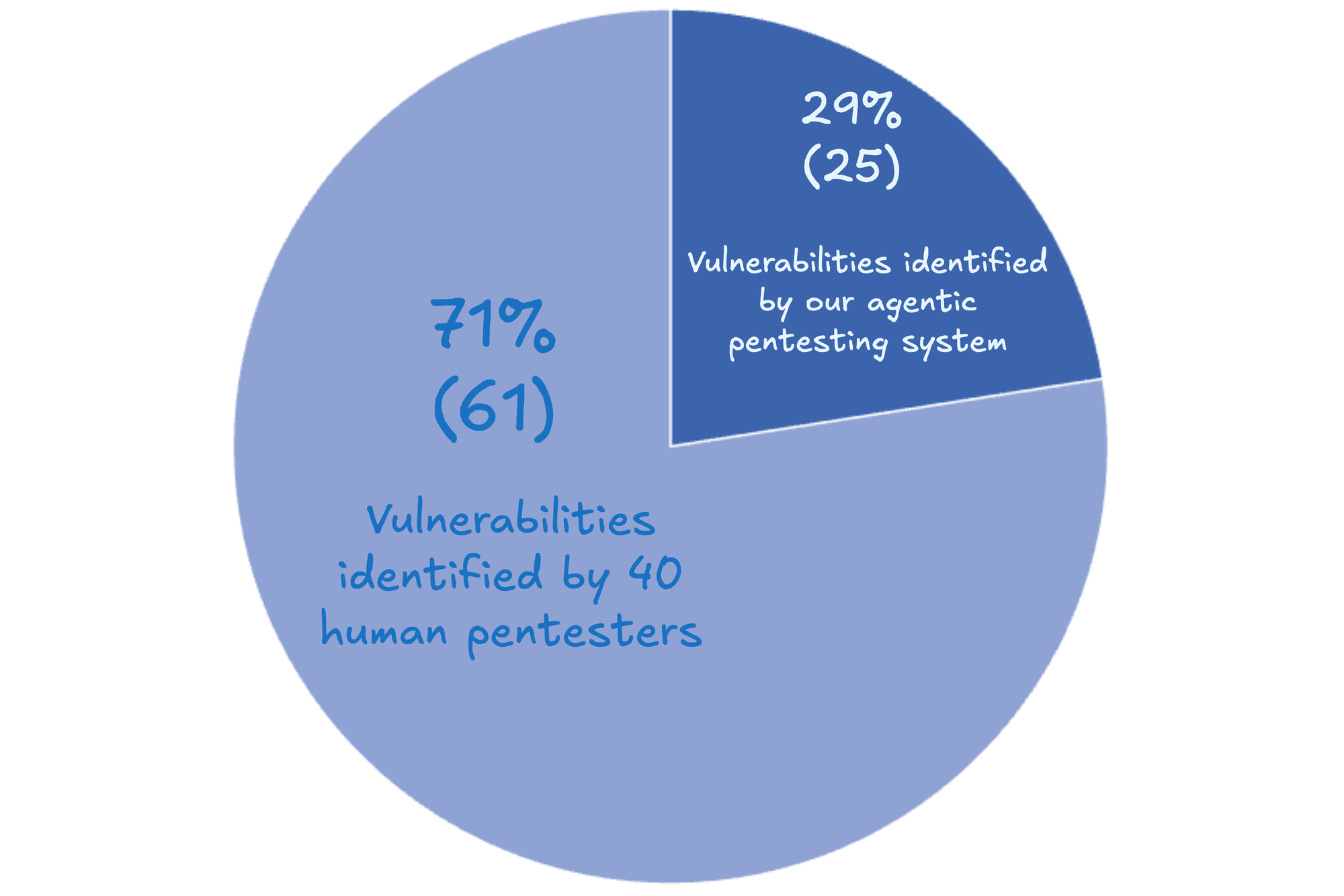
With the defence mechanisms in place, we took part in the precursor of the Government Bug Bounty Programme (pre-GBBP 15) in late 2025, where we tested staging systems (instead of production ones in the actual GBBP). In this man vs. machine competition (the other participating teams were 40 human pentesters), our system discovered 29% of the findings and was placed in the top three. This is a significant step towards AI-assisted, and eventually, fully autonomous pentesting!
Next Steps
With the success at Pre-GBBP, our agentic pentester is being built into a full-fledged production system by a dedicated engineering team from CSG. New exploit agents are also continually being added on top of the first five, some of which are shown in the overall system architecture above, using the easily extensible framework.
Learning Points
Looking back at the past year, here are our key takeaways:
Think Big, Start Small
When we started in June 2025, there were few architectures or playbooks for agentic pentesting. We took baby steps, first testing individual agents on easy CTF containers, then adding workflows and orchestrators, and finally layering in adaptive planning and skills. Each step built our confidence for the next.
Observe, Evaluate, Iterate
CTF containers gave us binary pass/fail benchmarks (flag captured or not), but we also needed to know whether changes brought us closer to success. Designing interim benchmarks proved extremely challenging and we had to rely heavily on studying Langfuse traces to make these assessments.
Use Human Experts for Guidance
Having Darrel, our expert pentester, on the team was invaluable. He helped us assess whether the system was taking the right path, got the team thinking like pentesters, and guided workflow design to match how a human would approach pentesting.
Maximising Cross-Domain Competency
Our team was a 50-50 split of cybersecurity engineers and AI engineers. Working closely without boundaries, knowledge flowed both ways. By the end, AI engineers were writing instructions to bypass defence mechanisms while cybersecurity engineers were optimising long-term memory management.
Acknowledgements
This project would not have been possible without the extensive contribution of:
- Chai Li Xian (Team Lead and Cybersecurity Engineer): Li Xian, the orchestrator, was instrumental in the success of this project. Under her leadership, the team moved fast and failed fast, experimenting with various approaches and pivoting, until we finally got things working. She was also heavily involved in designing the architecture, software engineering and stakeholder management.
- Darrel Huang (Pentester): Darrel, our expert pentester, was the model for the agentic pentesting system. He provided insights on how a pentester thinks and works, which led us to design an effective system. He also wrote tools for the agents and helped to validate that the vulnerabilities found were indeed valid.
- Joe Sunil Inchodikaran (Cybersecurity Engineer): Joe, the multi-tasker, had a hand in the system from end to end. Not only did he write skills based on his cybersecurity knowledge, he also designed the whole planning module to help the system strategise its moves.
- Isaac Lim (AI Engineer): Isaac, the strategist, used his deep AI expertise to help us fully utilise the power of agents and large language models for pentesting. He introduced the rolling summarisation approach to keep the context manageable, and was also actively doing system design and software engineering, even building a frontend for users to test our prototype in the early stages!
- Watson Chua (AI Engineer): Watson, the evaluator, was in charge of observability and evaluation. He ran the experiments on the datasets after each modification, and tracked the results to make sure that the system was moving in the right direction.

Concluding Remarks
The landscape of agentic pentesting has shifted dramatically since we embarked on this project a year ago. We’ve witnessed a surge in capability at both the agentic harness level (such as XBOW) and the underlying model level (notably Mythos). Given this rapid commercial evolution, a natural question arises: Why are we still building our own system?
For a government technology agency operating in a sensitive domain like cybersecurity, the answer is found in strategic autonomy and deep capability.
Why We Build
Building our own system isn’t about avoiding the market; it’s about ensuring we have a platform that is secure, understood, and adaptable. Our approach focuses on:
- Strategic Autonomy — By hosting the harness on our own infrastructure and implementing guardrails consistent with our own policies, we ensure that sensitive vulnerability data and operational logic remain within our control. This independence allows us to maintain a model-agnostic stance, ensuring we are never locked into a single provider’s ecosystem.
- Deepening Technical Capability — There is no substitute for the expertise gained through development. By building our own skills based on our pentesters' actual workflows, we gain a profound understanding of the internal mechanics of agentic AI. This "under-the-hood" knowledge is critical for troubleshooting, defending against adversarial AI, and staying ahead of the curve in an automated threat environment.
- Expanding Our Options — This project serves as a foundational "engine." Owning the harness provides us with more options to spin off and integrate other critical cyber hygiene tools. It allows us to address government-specific security needs that commercial products might overlook, providing a bespoke defence for the public sector.
A Collaborative Future
Choosing to build is not a rejection of the wider ecosystem; rather, it is a way to engage with it from a position of strength. This is not a zero-sum game:
- Iterative Improvement: As the field develops, we actively learn from the experiences of others and the breakthroughs in the open-source community to iteratively improve our own system.
- Strategic Focus: We can still leverage external products and models where appropriate. This gives us the bandwidth to focus our specialised engineering efforts on the most sensitive and complex challenges, rather than building every commodity component from scratch.
Ultimately, by prioritising strategic autonomy and deep capability, we ensure that we aren't just consumers of AI but also, the masters of it. This self-reliance ensures that our cyber defences remain agile, deeply understood, and prepared for the complexities of the future.